
Recursive Language Models (RLMs): From MIT’s Blueprint to Prime Intellect’s RLMEnv for Long-Horizon LLM Agents
Long-horizon agents don’t fail because they “can’t reason.” They fail because they can’t keep the right things in mind for long enough, cheaply enough, and reliably enough.
If you’ve used coding agents that read dozens of files, research agents that scan huge docs, or workflow agents that run multi-step tool chains, you’ve seen the symptoms:
-
token costs climb linearly with context length
-
accuracy drops as context grows (“context rot”)
-
summarization helps… until the task needs dense, exact access to many earlier details
-
tool outputs flood the context window with noise
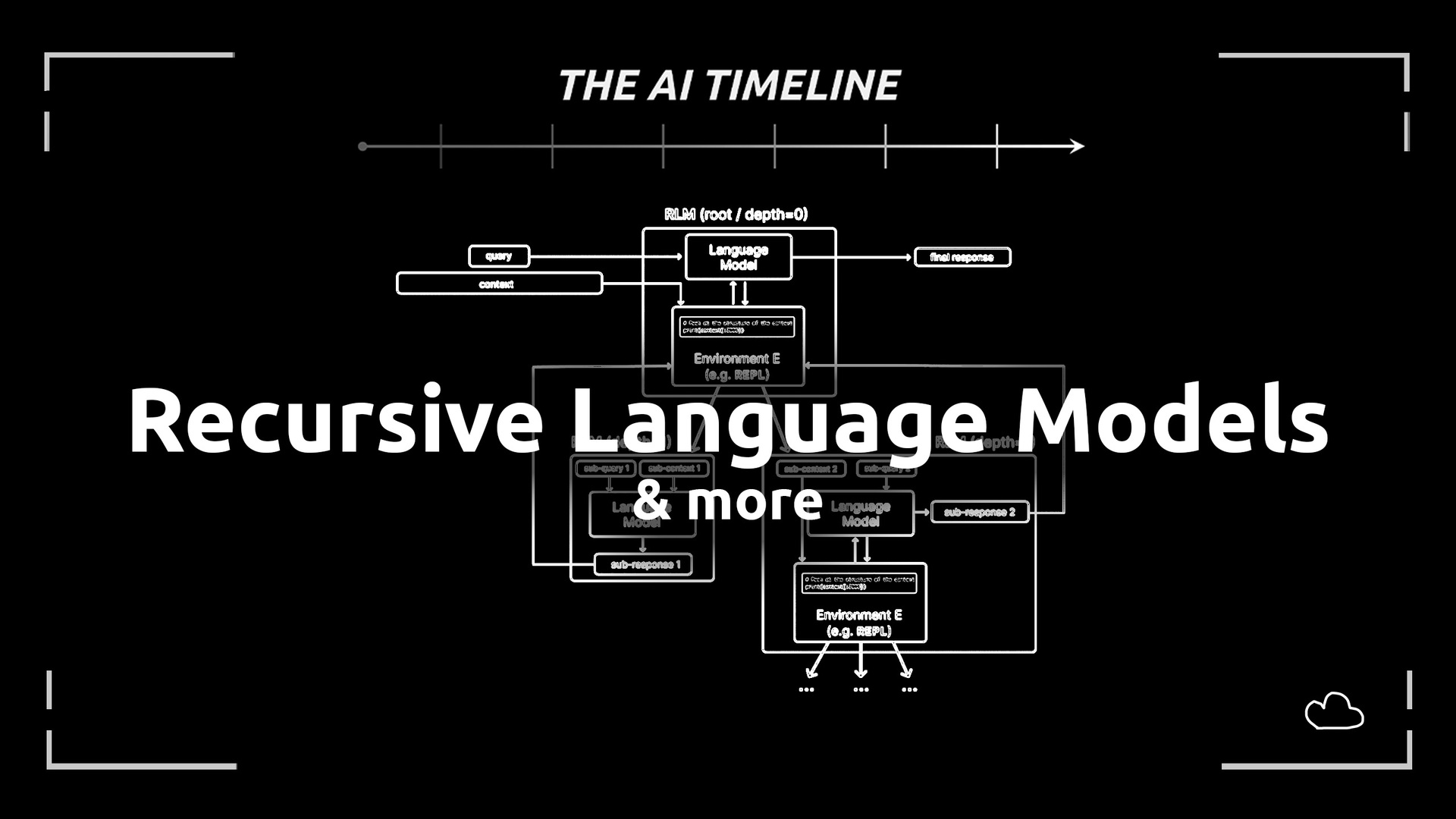
Recursive Language Models (RLMs) are an attempt to change the shape of the problem. Instead of forcing an LLM to ingest an ever-growing prompt in one giant pass, RLMs treat the prompt (and other large inputs) as part of an external environment the model can inspect programmatically—then recursively call itself on small, purposeful slices. arXiv+1
In early results from MIT CSAIL, RLMs handled inputs far beyond a base model’s context window while maintaining quality and keeping costs comparable (sometimes cheaper) than common long-context scaffolds. arXiv+1 And Prime Intellect quickly turned the idea into a practical, “plug-and-play” environment—RLMEnv—built into their verifiers stack, designed for real agent workloads and RL training. Prime Intellect+2Prime Intellect Docs+2
Let’s unpack what RLMs are, why they matter, and how Prime Intellect’s RLMEnv changes the game for long-horizon agents.
1) Why long context is still a trap
Modern frontier models can hold large contexts, but two hard limits remain:
Cost scales with tokens
Even if a model can accept 200K+ tokens, running many steps of an agent that repeatedly re-sends that context becomes expensive fast.
Performance degrades as contexts grow
Both research and practitioner experience report that models become less reliable when the context is long and messy—forgetting details, mixing facts, or missing needles in haystacks (“context rot”). arXiv+1
The classic workaround—summarize—breaks “dense access” tasks
Summarization/compaction methods assume old details can be safely compressed. That fails in tasks like:
-
legal/compliance reviews (exact clauses matter)
-
codebase changes (exact APIs and edge cases matter)
-
deep research (citations and precise claims matter)
-
debugging (small details from earlier logs matter)
MIT’s RLM paper explicitly points out that compaction is often not expressive enough when the solution requires dense access to many parts of the prompt. arXiv
So the question becomes:
Can we keep the model’s active context small, while still giving it full access to huge inputs—on demand?
That’s the core RLM move.
2) The MIT blueprint: RLMs as inference-time scaling
MIT CSAIL’s paper (“Recursive Language Models”) frames RLMs as an inference-time scaling strategy: use additional compute not by reading everything, but by strategically inspecting and decomposing the input and recursively invoking the model. arXiv
The key idea
An RLM exposes the same interface as an LLM—text in, text out—but internally:
-
The full prompt (even extremely large) is stored in an external environment (their prototype uses a Python REPL).
-
The model writes code to:
-
peek at the data
-
search/filter/slice it
-
construct sub-prompts
-
-
The model then recursively calls itself (or other LLM calls) on those smaller pieces.
-
It combines results into a final answer.
In the paper’s description, the prompt is loaded as a variable inside a Python REPL, and the model programmatically examines and decomposes it, calling itself over snippets. arXiv
Why recursion helps
Think of a huge prompt as a dataset. If you force the model to read it end-to-end every time, you’re doing the equivalent of scanning the entire disk for every query.
RLMs borrow the intuition of “out-of-core” systems: keep a small fast working memory, and fetch only what you need. arXiv
What “recursive” means here (practically)
Recursion is not philosophical—it’s operational:
-
A “root” model decides a plan and identifies what it needs.
-
It spawns sub-calls to:
-
summarize a section
-
answer a specific sub-question
-
extract key facts
-
check contradictions
-
-
Those sub-results come back as compact artifacts that the root model can reason over.
This is why RLMs can often keep the root context window relatively stable even as the input size explodes.
3) RLMs vs other long-context strategies
RLMs don’t replace retrieval, chunking, or summarization. They’re a different control strategy.
(A) “Just increase context length”
Pros: simplest UX
Cons: cost grows linearly; performance can degrade; tool output bloats context.
(B) RAG (retrieval-augmented generation)
Pros: fetches relevant chunks
Cons: retrieval errors can silently omit crucial info; struggles when relevance is multi-hop or requires scanning many regions.
(C) Summarization / context compaction
Pros: reduces token load
Cons: lossy; fails on tasks needing exact details across many places. arXiv
(D) Agent scaffolding with files (external memory)
Pros: keeps context short; stores state in filesystem
Cons: often still needs heavy summarization; “state” can become fragmented; still can suffer context rot in the running dialogue. Prime Intellect notes file-based scaffolding as common, but emphasizes the remaining cost/performance issues as contexts grow. Prime Intellect
Where RLMs fit
RLMs treat the input as external memory and make the model responsible for how to read it.
It’s closer to giving the model:
-
a programmable microscope (Python REPL)
-
a budget (limited REPL output returned to the model)
-
and the ability to spawn specialist workers (sub-LLM calls)
4) The “environment” is the secret weapon
Why put the prompt into a Python REPL at all?
Because code is a powerful compression and control tool.
Instead of “thinking in tokens,” the model can:
-
search text with regex
-
parse JSON / HTML
-
split documents by headings
-
compute statistics
-
build indexes
-
rank candidates
-
run structured extraction
-
keep intermediate state in variables
MIT’s paper illustrates this as: the model loads the prompt into the REPL and uses code to peek, decompose, and recursively invoke itself. arXiv
This matters for long-horizon agents because the agent’s world is increasingly data-rich:
-
repos, diffs, logs
-
PDFs, tables, transcripts
-
web pages, citations
-
telemetry, configs
RLMs are essentially an approach to make an LLM behave more like a data system—without retraining the base model.
5) Prime Intellect’s leap: from blueprint to RLMEnv
MIT’s work is a blueprint and research prototype. Prime Intellect took the concept and built it into a production-style agent/RL ecosystem.
Their January 1, 2026 post, “Recursive Language Models: the paradigm of 2026,” describes implementing “a variation of the RLM” as an experimental RLMEnv inside their open-source verifiers library, intended to be usable inside any verifiers environment and compatible with RL training via prime-rl. Prime Intellect+1
What is verifiers?
Verifiers is Prime Intellect’s library for creating RL environments and agent evaluations—basically a standardized way to define:
-
datasets/tasks
-
interaction protocols (multi-turn)
-
tools
-
reward functions / scoring
…and then run evaluation or training with OpenAI-compatible models and RL trainers. GitHub+1
What is RLMEnv?
RLMEnv is the environment wrapper that turns an ordinary model into an RLM-style agent inside this ecosystem.
Prime Intellect highlights two core modifications (compared to the simplest “LLM + REPL” idea):
-
Tools beyond Python REPL are only usable by sub-LLMs
-
The model provides its answer via an environment variable, not direct text output Prime Intellect
Let’s translate that into how long-horizon agents actually benefit.
6) Design choice #1: Keep the root model “lean”
Prime Intellect’s RLM approach makes the root model operate with only the Python REPL, while sub-LLM calls can be the ones that use heavier tools (search, file access, etc.). Prime Intellect+1
Why this is smart
Tools often produce tons of tokens:
-
web search results
-
large file dumps
-
logs
-
stack traces
-
long JSON outputs
If you pipe those directly into the root model’s context, you’re back to bloated contexts and context rot.
By delegating tool usage to sub-LLMs, you can:
-
let sub-LLMs do noisy work
-
return only compact summaries/extractions to the root
-
keep the root context stable and focused
This is an explicit motivation in Prime Intellect’s write-up: tools can produce a lot of tokens, so the main RLM doesn’t have to see them; it delegates tool-heavy work. Prime Intellect

7) Design choice #2: Parallel sub-LLM fan-out (llm_batch)
Prime Intellect adds a practical mechanism: the REPL exposes an llm_batch function so the root can fire off many sub-queries in parallel. Prime Intellect+1
This matters because long-horizon tasks are often decomposable:
-
“summarize each chapter, then synthesize”
-
“extract all requirements, then check code”
-
“scan logs for anomalies, then correlate”
Parallel fan-out turns “long serial thinking” into something closer to map-reduce:
-
map: many sub-LLMs process slices
-
reduce: root aggregates results
That’s a big deal for agent latency and for scaling to extremely large inputs.
8) Design choice #3: The answer variable and controlled termination
Instead of ending when the model prints a final message, RLMEnv uses an environment variable answer—a dictionary with:
-
"content": editable across turns -
"ready": when set toTrue, rollout ends and content is extracted Prime Intellect
This does two things:
-
encourages iterative drafting/patching (the model can refine
answer["content"]) -
avoids accidental termination (the model doesn’t “finish” just because it emitted a sentence)
For long-horizon agents, accidental termination is common—models often produce a plausible answer early. The ready gate forces a more deliberate finish.
9) Output throttling: forcing the model to use code, not print everything
Prime Intellect also limits how much REPL output is shown back to the model per turn (they mention a default cap like 8192 characters, adjustable). Prime Intellect
This is subtle but powerful:
-
If the model can just
print(big_text), it will. -
If printing is capped, it must learn to:
-
search and slice
-
extract specific segments
-
call sub-LLMs for targeted work
-
keep intermediate artifacts structured
-
In other words: the environment shapes behavior toward efficient context management.
10) What workloads benefit most?
Based on how RLMs and RLMEnv are designed, the biggest wins tend to come from:
Long-document QA with dense evidence
Legal, policy, technical specs, academic papers—where you must quote or ground answers in multiple sections. MIT’s RLM results emphasize outperforming common long-context scaffolds on diverse long-context tasks. arXiv+1
Codebase-scale agent tasks
Agents that must scan many files, reason across modules, and make consistent edits. Prime Intellect explicitly frames long contexts as crucial for agents editing large codebases. Prime Intellect
Tool-heavy workflows
Where raw tool output is huge (search results, logs). RLMEnv’s “tools only for sub-LLMs” is built exactly to prevent tool-token flooding. Prime Intellect
RL training for agentic behaviors
Prime Intellect built verifiers + prime-rl so environments can be used for evaluation and RL training. RLMEnv is intended to slot into this pipeline. GitHub+1

11) The bigger vision: training models to manage context end-to-end
Here’s where the story gets especially interesting.
MIT shows that you can get big gains without retraining by wrapping existing models with an RLM inference strategy. arXiv+1
Prime Intellect’s post argues the next step is to train models to manage their own context “end-to-end through reinforcement learning,” aiming for agents that can solve tasks spanning weeks to months. Prime Intellect+1
That hints at a shift similar to what happened with tool-use:
-
first: prompt-engineered tool usage
-
then: models trained to use tools well
RLMs could follow the same path:
-
first: scaffolding + REPL + recursion
-
then: models trained to be excellent at context foraging—finding, verifying, and composing evidence over massive external state
12) Practical takeaways: how to think about RLMs if you build agents
If you’re designing agent systems (even without Prime’s stack), RLMs suggest a few very practical architectural principles:
Keep a small “executive” context
Your root agent should see:
-
the user goal
-
the current plan
-
compact intermediate artifacts
Not raw dumps.
Treat big inputs as external state
Files, docs, logs, web pages: store externally and provide programmatic access.
Enforce budgets
Cap what can be printed back into the model. Budgets create pressure to use tools intelligently.
Use parallel decomposition
Fan-out sub-workers for scanning/summarizing, then synthesize centrally.
Separate “doing” from “reporting”
Let sub-workers do noisy work; let the root write the final coherent answer.
RLMEnv is essentially these principles encoded as a reusable environment. Prime Intellect+1
13) What to watch next
A few near-term questions will decide how big RLMs become:
-
Depth > 1 recursion
Prime Intellect notes their current implementation uses a recursion depth of exactly 1 and they plan to make it adjustable (including deeper recursion). Prime Intellect
Deeper recursion could enable hierarchical “teams of teams,” but it also introduces complexity: error compounding, compute blowups, and credit assignment for RL. -
Standardized “context environments”
If verifiers-style environments become common, we may get shared benchmarks and training protocols for long-horizon context management—similar to how tool-use evals matured. -
Hybrid RAG + RLM
RAG can fetch relevant chunks; RLM-style control can validate coverage, run multi-pass extraction, and fill gaps via targeted scans. -
Agent reliability
RLMs are promising, but agent systems also need:
-
verification
-
deterministic tooling
-
robust retry policies
-
safety controls for code execution
Prime Intellect’s sandboxed execution and environment-driven termination are steps in this direction. Prime Intellect+1
Conclusion: RLMs are “memory management” for agents
Recursive Language Models aren’t just “another long-context trick.” They’re a reframing:
Don’t make the model read everything.
Make the model decide how to read.
MIT’s blueprint shows that by treating the prompt as an environment and enabling recursive self-calls, models can handle inputs far beyond their native context limits with strong quality. arXiv+1
Prime Intellect’s RLMEnv then makes the idea operational for real agent stacks: sub-LLM tool delegation, parallel batch calls, sandboxed execution, and controlled answer finalization—built into an ecosystem designed for evaluation and RL training. Prime Intellect+2GitHub+2
If long-horizon agents are the future (and all signs say they are), then “context management” will be one of the core battlegrounds. RLMs are one of the most concrete, engineering-friendly ways to attack it—right now.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/early-disease-diagnosis-app/
https://bitsofall.com/disney-openai-sora-ai-video/
Tesla Loses Market Lead: How the EV Pioneer Is Facing Its Toughest Competition Yet
Tiny AI Models: How Small Is the New Big Thing in Artificial Intelligence?

