
NVIDIA Releases PersonaPlex-7B-v1: a real-time, full-duplex speech-to-speech model that keeps a persona
NVIDIA’s research labs have dropped PersonaPlex-7B-v1 — a 7-billion parameter, open-weight model that combines streaming speech understanding and speech generation in a single network. It’s designed specifically to make spoken AI conversations feel human: simultaneous listening and speaking, natural interruptions and backchannels, and persistent “persona” control (voice timbre + role) so the model can behave like a customer-service agent, narrator, or fictional character while still sounding natural.
Below I unpack what PersonaPlex is, why the architecture matters, how it compares to older pipelines, what you can realistically build with it, and important practical details (license, availability, compute). I’ll also flag shortcomings and ethical considerations you should plan for if you intend to deploy it.
What PersonaPlex-7B-v1 is (short answer)
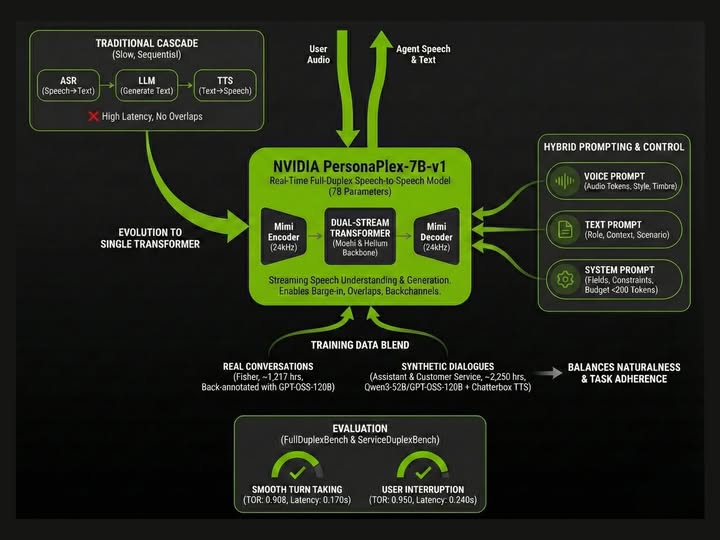
PersonaPlex-7B-v1 is a full-duplex, speech-to-speech transformer model that operates on continuous audio encoded by a neural codec and autoregressively predicts both text and audio tokens. Instead of the usual cascade (ASR → LLM → TTS), PersonaPlex ingests streaming encoded audio while simultaneously generating outgoing audio tokens — enabling rapid turn-taking, overlaps, barge-ins, and natural backchanneling (uh-huh, mm-hm) during live conversations. The system supports separate conditioning for (a) a voice prompt that sets the target timbre and style and (b) a text/system prompt that defines the persona, role, or scenario context.
Key high-level facts:
-
Model size: ~7 billion parameters (PersonaPlex-7B).
-
Full-duplex operation: listens and speaks at the same time (dual-stream Transformer).
-
Audio sampling / codec: uses Mimi encoders/decoders and supports high-quality 24 kHz audio.
-
Persona control: voice (audio prompt) + role (text prompt) for persistent persona behaviors.
-
Code & weights: model artifacts and code are hosted publicly (Hugging Face) under NVIDIA’s stated license terms.

Why the architectural shift matters
For years, voice agents used a cascade: Automatic Speech Recognition (ASR) → text LLM or dialog manager → Text-to-Speech (TTS). That approach has two structural problems:
-
Latency and unnatural rhythm. Each stage adds delay and forces strict turn boundaries: the system must fully stop listening while it thinks and speaks, making interruptions and overlaps awkward or impossible.
-
Lossy handoffs. Intermediate text alone discards prosody, speaker cues, and many subtle conversational signals that matter for backchannels and social timing.
PersonaPlex’s full-duplex design removes the rigid pipeline: the same model maintains context, processes incoming encoded audio incrementally, and emits outgoing audio tokens concurrently. That enables natural conversational dynamics — interruptions, simultaneous brief utterances, and reactive backchannels — while keeping persona control intact (voice + role). For real-world human-facing agents, that difference is huge: natural timing makes interactions feel alive rather than robotic.
How PersonaPlex works (technical overview)
PersonaPlex builds on prior full-duplex ideas (e.g., Moshi family) but explicitly adds persona conditioning and a production-minded codebase:
-
Dual-stream transformer: One stream ingests encoded, framed audio tokens (the “listen” stream) while the other outputs audio tokens (the “speak” stream). Both streams share internal state so generated speech reflects the user’s immediate input.
-
Neural codec tokens: Audio is encoded into a sequence of discrete codec tokens (neural codec) enabling autoregressive modeling of audio at token level; PersonaPlex can therefore predict future audio waveforms directly rather than generating an intermediate spectrogram. Mimi encoders/decoders at 24 kHz are referenced in the release notes.
-
Text + audio joint output: The model can output text tokens (useful for transcripts, moderation, downstream agents) as well as audio tokens (the actual speech output). That joint prediction helps the model maintain semantic fidelity while optimizing natural speech delivery.
-
Persona conditioning: Before runtime you provide a voice prompt (sample audio tokens that set timbre and style) and a text/system prompt (role, business context, persona specifics). The model then aims to obey the role while preserving natural conversational dynamics.
This mix gives developers both control and realism — historically a tradeoff that forced a choice between either custom voices/roles or naturalness; PersonaPlex promises both.
Practical capabilities & demo impressions
Early writeups, demos, and the Hugging Face release suggest the following capabilities and behavior patterns:
-
Real-time conversational flow: PersonaPlex can “barge in” and resume speaking when appropriate, producing short backchannels and supporting overlapping speech. That produces more human-like exchanges than a stop-start assistant.
-
Multi-role deployment: Use cases include customer support agents that keep a brand voice, interactive storytellers, in-game NPCs that respond naturally to player interruptions, and voice-first companions with consistent personalities.
-
Transcription + speech output: Because it can also generate text tokens, you can extract live transcripts or feed the text to downstream services (analytics, routing, moderation) while still producing spoken audio.
-
Local testing & community feedback: The model and sample notebooks are already on Hugging Face and community members report local installs and demos (videos and discussions present in the model repo). That indicates the release is not just academic but immediately usable.
How PersonaPlex compares with alternatives
-
Classic ASR→LLM→TTS stacks: PersonaPlex wins on conversational naturalness and latency for real-time talk scenarios. Traditional cascades still have the advantage in modularity (you can swap in specialized ASR or TTS models), but lose timing and overlap handling.
-
Other full-duplex models (Moshi family, etc.): Previous full-duplex systems achieved naturalness but often locked voice and role (a single persona voice). PersonaPlex’s novelty is preserving persona control (voice + role) while remaining full duplex. That is the key differentiator.
-
Commercial voice assistants: PersonaPlex’s openness (weights and code) means startups and researchers can iterate quickly; commercial closed systems might still have edge-case polish, moderation pipelines, and integrations, but lack the open experimentation path PersonaPlex enables.
Possible applications (realistic examples)
-
Humanlike customer service agents: Agents that can interrupt politely when the caller starts speaking, offer quick backchannels (“I hear you”), and retain a company persona voice for brand consistency.
-
Interactive entertainment / gaming: NPCs that respond mid-utterance to player quips, keep a character voice, and adapt to player tone and interruptions.
-
Accessibility and assistive tech: Companions that maintain conversational flow for people with communication disabilities who need natural timing and responsive spoken confirmations.
-
Live dubbing and roleplay: Real-time voice conversion + persona control could be used to dub performances or create live roleplay characters with consistent voices and behaviors.
-
Hybrid human-AI collaboration: In scenarios like broadcast or live radio, an AI partner that can produce timely backchannels and maintain persona while not stealing the floor.
Deployment considerations: compute, safety, and licensing
Compute: While the 7B size is relatively modest compared to ultra-large models, full-duplex audio token generation at 24 kHz still requires nontrivial real-time compute (fast autoregressive decoding, neural codec inference). Expect need for GPUs for production real-time throughput; advanced quantization and optimized runtimes will help on-prem or edge deployments. Community posts indicate people are testing locally, but production SLAs will require careful engineering.
Licensing & terms: The model artifacts are distributed via Hugging Face under NVIDIA’s stated license terms (the code and model repo list licensing; weights may be governed by the NVIDIA Open Model License and code under permissive terms — check the model page for the exact license files before commercial use). Always confirm the repo license text to ensure your planned use (commercial or otherwise) complies.
Safety & misuse risks: Any high-quality speech synthesis model raises voice-cloning and impersonation risks. Persona control and voice prompting make it convenient to craft brand or celebrity voices — that’s powerful but also hazardous. Deployers should:
-
implement voice consent checks and provenance markers,
-
use watermarking or steganographic audio markers where possible,
-
maintain robust content moderation for harmful or deceptive speech, and
-
follow jurisdictional rules about voice use and biometric likeness.
NVIDIA’s research notes discuss persona prompts and system prompt controls; operational deployments must add policy and monitoring layers above the model.
Benchmarks & early reception
Preliminary coverage and community threads show excitement: reviewers praise the naturalness and persona control tradeoff. Benchmarks shared in release materials suggest PersonaPlex outperforms cascaded systems on conversational dynamics and task adherence (metrics that reward backchannel accuracy, interruption handling, and persona alignment). Community testing and early demo videos are already circulating, indicating hands-on interest and rapid experimentation. As always, independent benchmarks will be needed to validate claims across languages, accents, and noisy environments.
Limitations & open questions
-
Robustness in noisy/multi-speaker settings: While designed for streaming speech, real-world environments with multiple overlapping speakers and background noise present challenges for codec encoding and speaker attribution. How PersonaPlex handles diarization and speaker tracking at scale remains an important question.
-
Language and accent coverage: Early notes focus on English; multilingual and low-resource accent performance must be validated.
-
Latency vs. quality tradeoffs: Autoregressive audio token generation at high sample rates is computationally intensive; reducing latency without sacrificing voice quality requires clever decoding strategies and optimized runtimes.
-
Ethical safeguards: Technical mitigations for impersonation are not a solved problem — policy and product design must lead here.
How to try it (where to start)
-
Model repo & assets: The PersonaPlex-7B-v1 repo and artifacts are hosted on Hugging Face (model files, example notebooks, and discussions). That’s the first stop for code, sample prompts, and license files.
-
Research overview & technical paper: NVIDIA Research’s PersonaPlex project page provides the design rationale, architecture diagrams, and conceptual results. Read that to understand persona prompts and dual-stream operation.
-
Community guides & demos: Several early community posts and an installation/testing video are already available; these are useful to see real-world installation and latency tradeoffs.
Final thoughts: why this release matters
PersonaPlex-7B-v1 is an important step toward truly conversational voice AI. It addresses a longstanding tension in voice systems — the tradeoff between natural conversational dynamics and persona/voice control — by combining streaming audio understanding and speech generation into one conditioned model. For developers of voice agents, virtual companions, and interactive entertainment, that combination unlocks new interaction patterns that were previously awkward or impossible.
At the same time, the release underscores responsibilities: the technical capability to produce convincing, persona-driven voices heightens risks of misuse. Any deployment should pair PersonaPlex’s power with strong provenance, consent, and moderation mechanisms.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/seta-rl-terminal-agents-camel-toolkit/
https://bitsofall.com/google-ai-ucp-agentic-commerce/
Google AI Releases MedGemma-1.5: A Major Upgrade for Open Medical Imaging + Text AI

