
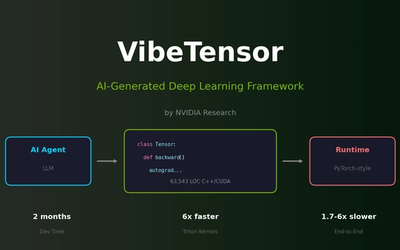
NVIDIA AI Release VibeTensor — What it is, why it matters, and what comes next
Summary (TL;DR): The NVIDIA AI Release VibeTensor represents a new generation of compute architecture and developer tools aimed at making high-throughput, low-latency AI inference and mixed training-inference workloads more efficient across cloud, data center, and edge. VibeTensor combines architectural advances in tensor compute, a developer-friendly SDK, and systems-level integrations to help organizations scale next-generation generative AI and real-time multimodal workloads while reducing power and cost per inference.
Introduction
NVIDIA has spent the last decade building hardware and software that power modern AI — from GPUs and tensor cores to CUDA, cuDNN, and full software stacks for training and inference. The NVIDIA AI Release VibeTensor continues that trajectory by packaging new microarchitectural improvements with a focused software ecosystem to address two converging pressures: the explosive demand for low-latency generative AI services, and the need to run increasingly capable models in power- or cost-constrained environments.
This article explores what VibeTensor brings to the table, why it’s important for developers and enterprises, how it integrates with existing NVIDIA tooling, and what to expect as the ecosystem matures. The goal is to give you a clear, practical view — whether you’re an ML engineer, a CTO evaluating infrastructure, or a product manager planning a rollout.
What is VibeTensor? — A high-level description
At a high level, VibeTensor is a combined hardware-software initiative designed to accelerate tensor operations (the matrix math at the heart of deep learning) and simplify deployment. It’s best thought of as three tightly-coupled parts:
-
Microarchitecture/Tensor Accelerator — improvements to the core tensor compute pipeline that increase throughput for floating-point, mixed-precision, and quantized computations while improving energy efficiency and memory bandwidth utilization.
-
VibeTensor SDK and Runtime — a developer-facing software layer that provides optimized kernels, a runtime scheduler, and seamless bindings for PyTorch, TensorFlow, and ONNX-based inference paths. It includes tools for quantization-aware conversion, model sharding, and adaptive batching.
-
Systems Integration and Tooling — cluster orchestration enhancements, profiling and observability, and reference architectures for cloud, on-prem, and edge devices to make operationalization smoother.
These three layers aim to reduce both the raw cost of compute (ops per joule) and the developer/operator cost of delivering production AI.

Key technical advances (what’s new under the hood)
While the precise engineering details are deep, here are the core technical themes usually associated with a release like VibeTensor:
1. Smarter tensor engines
-
New micro-op fusion and wider inner-product pipelines that accelerate common transformer building blocks (multi-head attention, scaled dot products, and feedforward layers).
-
Improved support for low-bit precisions (8-bit, 4-bit, and mixed 2/4-bit modes) while keeping model accuracy high through better quantization schemes.
2. Memory and bandwidth optimizations
-
On-chip memory architecture tuned to reduce DRAM traffic for sequence models and large context windows.
-
Adaptive prefetching and tiling that automatically reorganize tensors for maximum compute density.
3. Deterministic low-latency runtime
-
A scheduler that minimizes jitter for real-time inference (important for interactive apps like voice assistants, AR/VR, and live multimodal agents).
-
Priority-aware queues and adaptive batching so that latency-sensitive requests don’t get stuck behind bulk batch jobs.
4. First-class multimodal support
-
Native kernels and fused operations for common vision-language blocks, multimodal attention, and cross-encoder patterns — enabling more efficient audio+vision+text pipelines.
5. System-level energy efficiency
-
Power-aware throttling and per-kernel power guidance to optimize for performance-per-watt across different deployment scenarios (cloud racks vs edge servers).
Developer experience — tools that matter
A release succeeds when developers can adopt it without massive rewrites. VibeTensor emphasizes that with these software features:
-
Seamless integration with PyTorch/TensorFlow: Drop-in optimized operators and backends that accelerate existing models with minimal code changes.
-
Quantization and compression toolchain: A guided path to 8-bit and 4-bit conversion while preserving accuracy via calibration and mixed-precision fallback.
-
Profiling and observability: End-to-end tracing of model latency, memory usage, and power consumption, plus actionable optimization tips (e.g., layer fusion, batch sizing).
-
Model export compatibility: Strong ONNX and TorchScript support to move models from training clusters to inference fleets easily.
-
Reference architectures & Helm charts: For Kubernetes-based deployments, serverless inference wrappers, and edge deployment blueprints.
These improvements reduce friction in moving from research prototypes to production-grade services.
Real-world use cases — who benefits most?
NVIDIA AI Release VibeTensor targets workloads where throughput, latency, and efficiency matter at scale. Typical beneficiaries include:
-
Conversational AI and virtual assistants: Lower latency for multi-turn conversations, especially with long context windows.
-
Generative AI services: Faster text, audio, and image generation for cloud services and hosted APIs — improving cost-per-token and responsiveness.
-
Real-time multimodal apps: AR/VR, live captioning, and video understanding that need synchronized audio-vision-text pipelines.
-
Edge inference at scale: Retail kiosks, robotics, and IoT gateways that need stronger compute in constrained power envelopes.
-
Enterprise retrieval-augmented generation (RAG): Faster vector search and re-ranking for knowledge-augmented responses.
Performance and efficiency — realistic expectations
Architecture claims can be exciting, but deployers need grounded expectations:
-
Throughput improvements: Expect substantial improvements for transformer-heavy workloads, particularly when using supported quantized modes and fused kernels.
-
Latency variance: The deterministic runtime aims to reduce jitter, which is crucial for interactive products — but system-level latency still depends on network, orchestration, and data preprocessing.
-
Energy and TCO: Organizations concentrating on inference cost will often find better performance-per-watt and lower total cost of ownership, especially when combined with optimized batching and autoscaling.
Always benchmark with your models and representative data; synthetic benchmarks rarely reflect production workloads.
Integration with existing NVIDIA stack
VibeTensor is designed to be compatible with the broader NVIDIA ecosystem:
-
CUDA/cuDNN compatibility: Existing NVIDIA developer investments remain valuable — many optimizations are delivered as new libraries rather than an entirely new programming model.
-
Triton Inference Server: Expect updated Triton backends to leverage VibeTensor kernels for serving at scale.
-
NVIDIA NGC models and containers: Prebuilt containers and optimized model versions can accelerate adoption.
-
Fleet management: Integration points for cluster schedulers and observability tools to monitor utilization and health.
This layered approach minimizes migration friction for teams already invested in NVIDIA tooling.
Deployment patterns and architecture recommendations
To get the most out of the NVIDIA AI Release VibeTensor, teams typically follow these patterns:
-
Pilot with representative models
-
Start small with one service (e.g., chatbot or image encoder) and run comparative benchmarks (throughput, latency, power).
-
-
Adopt mixed-precision and quantization
-
Convert candidates to 8-bit or 4-bit modes where possible, using the provided toolchain and validation suites.
-
-
Hybrid fleet design
-
Use VibeTensor-accelerated nodes for latency-critical paths and standard GPU nodes for heavy training.
-
-
Use adaptive batching and priority queues
-
Separate online interactive traffic from bulk batch inference to minimize latency spikes.
-
-
Edge vs cloud trade-offs
-
For edge deployments, prioritize power-efficient modes and smaller, distilled models; for the cloud, maximize throughput with larger context windows.
-
These practices balance performance, cost, and user experience.
Challenges and considerations
No technology is a silver bullet. Here are important caveats:
-
Model compatibility: Some custom ops or research prototypes may require additional porting work to fully utilize new kernels.
-
Accuracy trade-offs: Aggressive quantization reduces precision and can degrade outputs unless managed carefully.
-
Operational complexity: New runtimes and power-management knobs increase the operational surface area; teams need good observability and automation.
-
Vendor lock-in concerns: Deep integration into a vendor’s optimized stack can accelerate time-to-market but may reduce portability.
Careful pilot programs and a staged migration help mitigate these risks.
Business impact — cost, speed, and differentiation
From a business perspective, VibeTensor can influence three levers:
-
Lower cost-per-inference: Through efficiency gains, organizations can operate large-scale generative services more cheaply or increase margins.
-
Faster time-to-interaction: Reduced latency improves user experience for interactive applications (e.g., chat, AR), which can directly affect retention and conversion.
-
New product capabilities: Better multimodal support and long-context efficiency enable products that were previously too expensive or slow to ship.
Enterprises should run ROI analyses focused on the parts of the stack that matter for their use cases (inference-heavy workloads, or real-time interactive systems).
How to evaluate VibeTensor for your organization (checklist)
-
Do you have latency-sensitive AI workloads?
-
Are you running transformer-heavy models in production?
-
Is inference cost a material part of your operating expense?
-
Do you need better support for multimodal or long-context models?
-
Can your engineering team adopt new runtime tools without blocking product roadmaps?
If you answered “yes” to one or more, VibeTensor is worth a pilot.
Example migration plan (90-day pilot)
Week 0–2 — Discovery & baseline
-
Identify target model(s) and collect representative traffic.
-
Run baseline benchmarks on current infrastructure.
Week 3–6 — Port & optimize
-
Convert models using the VibeTensor toolchain (quantize, fuse ops).
-
Integrate with Triton or your inference stack.
Week 7–10 — Validate & stress test
-
Run accuracy validation, load tests, and power profiling.
-
Monitor for edge cases and degradations.
Week 11–12 — Rollout & measure
-
Gradually route a percentage of traffic to VibeTensor nodes.
-
Track cost, latency, error rates, and user metrics.
This staged approach reduces risk and surfaces real-world benefits or issues quickly.
Ecosystem and community impact
Major releases like VibeTensor typically spur ecosystem activity:
-
Framework updates and community-contributed kernel optimizations.
-
Pretrained model variants optimized for low-precision and fused kernels.
-
Third-party tools for profiling, model conversion, and deployment automation.
Active community engagement speeds maturity and practical adoption patterns.
Conclusion
The NVIDIA AI Release VibeTensor is an evolutionary step in the long arc of AI infrastructure: focused microarchitectural gains, pragmatic developer tooling, and systems-level integration to make high-performance AI more accessible and cost-effective. Whether you’re building a latency-sensitive conversational agent, deploying multimodal pipelines, or optimizing inference cost at scale, VibeTensor offers concrete levers to pull — but success depends on careful benchmarking, measured rollout, and attention to accuracy and operational complexity.
If you’re curious about practical next steps: pick a representative workload, run a short pilot, and compare not just synthetic FLOPS numbers but real user-facing metrics like p95 latency, cost-per-request, and failure modes. Those are the figures that will tell you whether VibeTensor moves the needle for your business.
FAQ — Quick answers
Q: Is VibeTensor suitable for edge devices?
A: Yes — one of the release goals is improved power efficiency and quantized modes that make it viable for edge servers and powerful gateways. For ultra-constrained devices, distilled models are still recommended.
Q: Do I need to rewrite my models?
A: Usually not from scratch. The SDK aims for drop-in accelerated operators, but custom ops or research code may need porting.
Q: Will model accuracy suffer with VibeTensor’s low-bit modes?
A: Not necessarily. With proper quantization-aware techniques and mixed-precision fallbacks, many models maintain accuracy. Always validate with your datasets.
Q: How does this affect training?
A: VibeTensor emphasizes inference and mixed workloads, but many optimizations also benefit fine-tuning and low-latency training loops.
Q: How to measure benefits?
A: Use real-world benchmarks: p50/p95 latency, throughput, power draw during steady-state, and total cost per query.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/biomimetic-models-nature-inspired-ai-engineering/
https://bitsofall.com/spacex-and-xai-merger/
Google Releases Conductor: a Context-Driven Shift for AI-Assisted Development
Rare Disease Diagnosis: Challenges, Breakthroughs, and the Future of Early Detection

