
Microsoft Unveils Maia 200 — The Inference Accelerator Built to Rethink Cloud AI Economics
Introduction — why “Microsoft Unveils Maia 200” matters
When Microsoft unveils Maia 200, it’s not just another chip press release. It signals a step change in how hyperscalers approach the economics of large-scale AI inference. Maia 200 is engineered specifically to lower the cost and energy footprint of generating tokens and running reasoning workloads across cloud services — a design goal that aligns with the rising realization that inference (not training) is the operational cost driver for today’s AI businesses. Microsoft’s announcement positions Maia 200 as a high-performance, narrow-precision inference accelerator intended for Azure, research partners, and internal services such as Microsoft 365 Copilot and Microsoft Foundry.
What is Maia 200? Quick technical snapshot
At its core, Maia 200 is a custom in-house AI accelerator focused on inference. Key technical highlights Microsoft and reporting outlets have emphasized include:
-
Fabrication on TSMC’s 3nm process node (leading edge).
-
Native FP4 and FP8 tensor cores optimized for low-precision, high-throughput matrix math — the sweet spot for language model inference.
-
Large on-chip and HBM memory: reported specs include ~216GB of HBM3e memory with multi-TB/s bandwidth and several hundred MB of SRAM for a dense, hierarchical memory system.
-
Very high peak integer/FP throughput: Microsoft cites >10 petaFLOPS at FP4 and >5 petaFLOPS at FP8 in aggregate.
-
Ethernet-based scale-up fabric and architectural elements intended to let clusters of Maia 200s scale to thousands of accelerators.
Those specs show a clear design target: make each Maia 200 extremely efficient at the matrix multiplies and memory moves that dominate inference costs for LLMs, and to do so inside Microsoft’s Azure datacenter fabric.

Why Microsoft built Maia 200 (and why that matters to enterprises)
Two trends pushed Microsoft and others to design bespoke AI silicon:
-
Inference is expensive at scale. As models get larger and are deployed for millions of users, per-token costs accumulate. Custom silicon optimized for inference precision (FP4/FP8) can dramatically reduce cost per token versus general-purpose GPUs. Maia 200 is explicitly framed as an answer to that challenge.
-
Vertical integration reduces fragility in supply and pricing. By owning chip design and the full hardware + software stack, cloud providers can better control pricing, performance tuning, and scheduling for proprietary services (like Microsoft 365 Copilot), while still using third-party chips where appropriate. Microsoft’s messaging makes clear Maia 200 is part of a broader end-to-end infrastructure strategy — not a wholesale replacement of partners.
For enterprises, the practical upshot is potentially cheaper inference options in Azure over time, improved latency and reliability for Microsoft services, and more choices when architecting production ML deployments.
How Maia 200 compares to the competition
Microsoft framed Maia 200 as competitive with other hyperscaler silicon. Reported comparisons highlight:
-
Compared to Amazon Trainium (Gen 3): Microsoft says Maia 200 delivers multiple× the FP4 performance in common inference workloads. Independent reporting echoes that Maia 200 targets a higher FP4 throughput for token generation.
-
Compared to Google TPU v7 / other TPUs: Maia 200 emphasizes FP8 performance gains in some workload mixes, where FP8 maintains model quality while enabling denser, cheaper compute.
-
Compared to NVIDIA Blackwell / high-end GPUs: Maia 200 is positioned as a cost-efficient inference option rather than a wholesale GPU replacement. Microsoft makes a nuanced argument — custom silicon can displace GPUs in many inference scenarios, but GPUs remain useful for training and other heterogeneous workloads. Several outlets note Microsoft will still rely on third-party accelerators alongside Maia 200 where needed.
The reality is nuanced: Maia 200 will likely shine in production inference fleets where the same optimized LLMs run billions of tokens; GPUs retain advantages in training, mixed workloads, and where software ecosystems are deeply invested in CUDA tools.
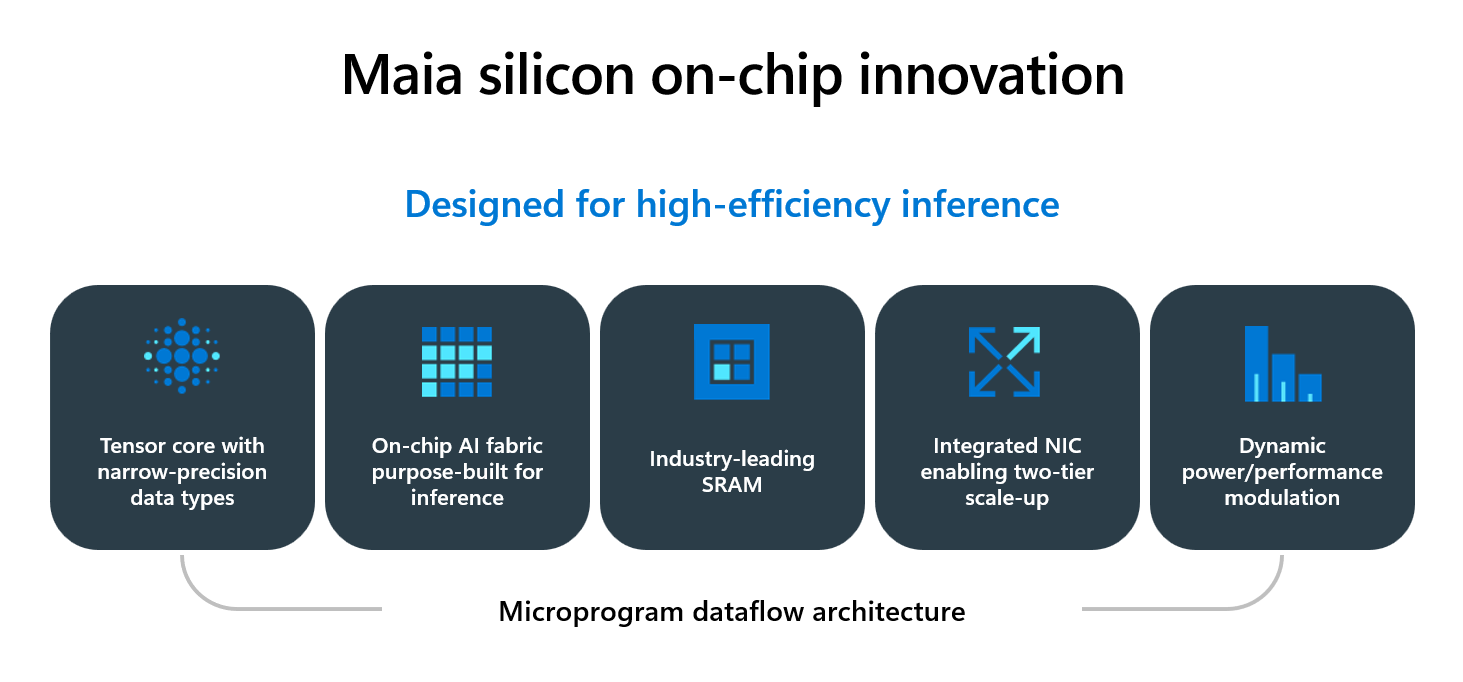
Architecture highlights that matter for real workloads
When engineers evaluate a new accelerator, the headline FLOPS number is only part of the story. Maia 200’s architecture introduces a few meaningful features:
-
FP4 / FP8 native support: Low precision arithmetic reduces memory bandwidth pressure and boosts compute density for transformer matrix multiplies. This matters directly for token cost in LLMs.
-
Large HBM3e capacity with high bandwidth: The combination of high capacity (reported 216GB) and ~7 TB/s bandwidth lets Maia 200 hold substantial model state close to the accelerator, reducing off-chip data transfers that can bottleneck throughput.
-
On-chip SRAM and a redesigned memory hierarchy: Microsoft emphasizes a multi-level cache strategy (hundreds of MB of SRAM) that enables better tile-level data locality — useful for the small, repeated matrix multiplies in transformer layers.
-
Ethernet scale-up fabric: Rather than a proprietary interconnect, Maia 200’s fabric design focuses on scaling clusters using standard Ethernet at scale, simplifying datacenter integration and leveraging existing networking investments.
Together, these features are aimed at maximizing utilization (keeping compute busy) and minimizing the “data movement” tax that often kills real-world throughput.
What this means for Azure, Microsoft services, and partners
Microsoft stated it’s already deploying Maia 200 in Azure US Central and plans staged rollouts to other regions. Early internal uses include Microsoft Foundry and Microsoft 365 Copilot, where inference efficiency directly affects margins and user experience. By introducing an SDK and early access programs, Microsoft also signals a willingness to let researchers and partners tune workloads for Maia 200.
For customers this implies:
-
Lowered inference costs (eventual): As Maia 200 capacity grows in Azure, customers running inference-heavy workloads could see reduced cloud bills or better price/performance options.
-
Optimized Microsoft services: Copilot and other Microsoft experiences could improve in latency, reliability, and cost predictability as they migrate suitable inference to Maia-backed fleets.
-
Need for software adaptation: To realize the best gains, model and inference stacks will need to adopt FP4/FP8 quantization and make use of the SDK Microsoft offers. Enterprises using open-source toolchains will need to test and possibly tune models for Maia 200’s precision and memory hierarchy.
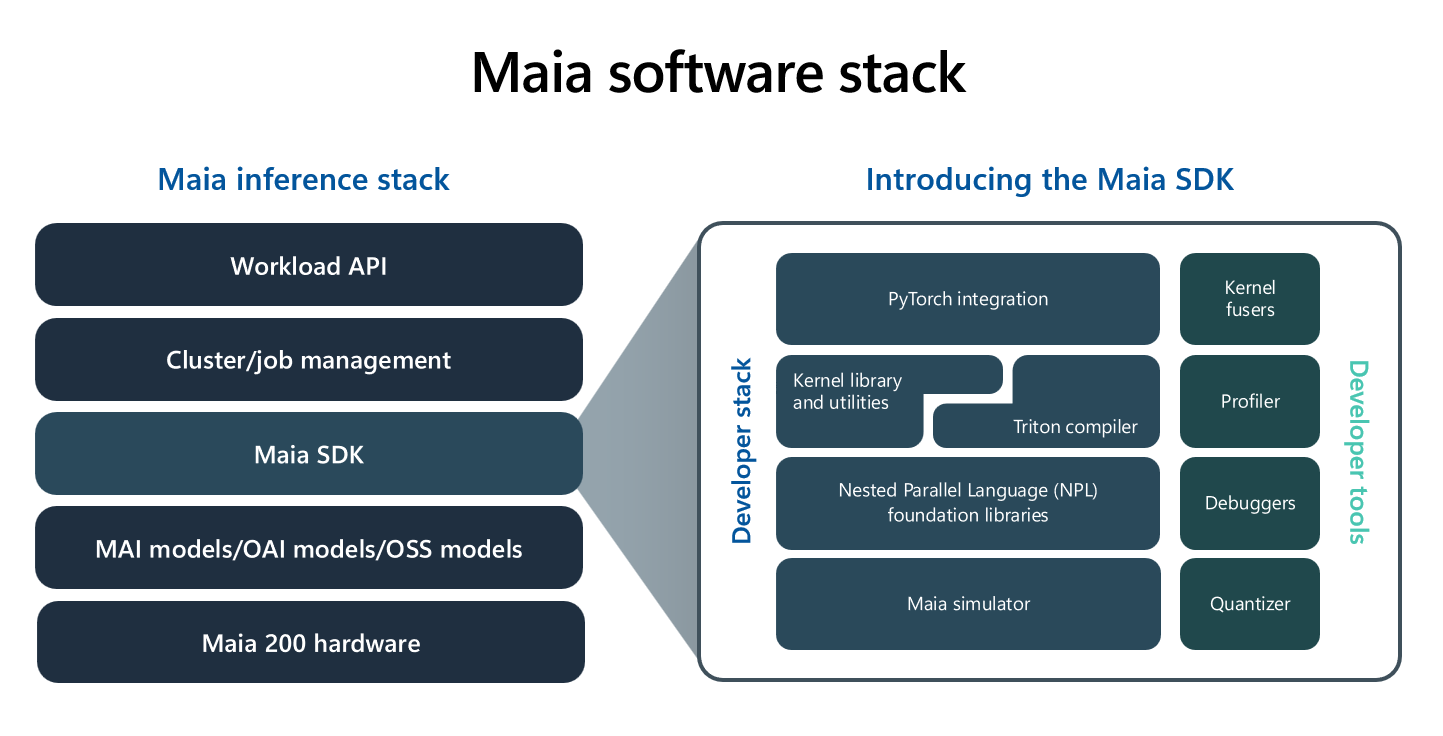
Developer and ecosystem considerations
Microsoft announced early access tooling and SDKs targeted at researchers and open source contributors. That’s important: hardware matters only if the software ecosystem supports it. Expect:
-
Quantization toolchains and model converters to produce efficient FP4/FP8 kernels.
-
Runtime libraries and graph compilers tailored to Maia 200’s memory hierarchy and scale fabric.
-
Profilers and cost-analysis tools that show token-level economics so teams can decide when to deploy to Maia fleets.
Open source adoption and third-party frameworks’ support will dictate how fast non-Microsoft workloads migrate to Maia 200.
Environmental and efficiency claims
Microsoft emphasizes performance-per-dollar and performance-per-watt improvements: the company claims Maia 200 is significantly more efficient than earlier systems, reducing both operating cost and energy demands for inference clusters. Independent reporting highlights a 30% improvement in performance-per-dollar relative to Microsoft’s previous in-house systems. Those gains can translate into lower carbon intensity per token if paired with clean datacenter energy, but the detailed lifecycle and manufacturing emissions of any new 3nm chip remain a separate debate.
Commercial availability and roadmap
Important practical notes:
-
Not a retail card: Maia 200 is designed for Azure datacenters and internal Microsoft infrastructure; it’s not being sold as a standalone card to consumers or third-party OEMs.
-
Staged Azure rollouts: Microsoft is deploying Maia 200 in specific Azure regions first, with broader rollout planned as production capacity scales.
-
SDK and early access: Microsoft is offering developer access to SDKs and tools — a critical move for community adoption.
In short, enterprises should view Maia 200 as a cloud option (in Azure) rather than a hardware purchase option for on-premises clusters.
Practical advice for teams planning to leverage Maia 200
If you manage ML infrastructure, here are steps to prepare for Maia 200 adoption:
-
Audit inference workloads: Identify hot paths and high-volume inference endpoints where per-token costs are material. Those are the most likely candidates for Maia migration.
-
Experiment with quantization: Test FP8 and FP4 quantization strategies now. Understand quality/perf tradeoffs for your models.
-
Profile end-to-end latency and memory footprint: Maia 200’s strength is often in reduced data movement; tune your model graph to reduce off-chip transfers.
-
Engage with Microsoft’s early access SDK: If you’re an Azure customer, apply for early access or follow the SDK docs to port a test workload.
-
Plan for hybrid fleets: Expect a hybrid future where GPUs, third-party accelerators, and Maia 200 coexist. Strategy should be about matching workload to the best substrate.
Strategic and market implications
Microsoft’s move is part of a broader trend: hyperscalers are vertically integrating across hardware, software, and cloud services to optimize AI economics. While Maia 200 won’t instantly dethrone incumbents, it increases competition and provides customers more options — which can pressure pricing and spur innovation across the ecosystem. Importantly, Microsoft made clear that it will continue buying third-party accelerators where they make sense; this is strategic diversification, not single-vendor lock-in.
For the industry, competition between custom silicon efforts (Maia 200, Trainium, TPUs, and NVIDIA’s roadmap) should accelerate improvements in both hardware and inference software.
Risks and open questions
No product launch is without tradeoffs. Some open questions to watch:
-
Model compatibility and conversion complexity: How well will existing production models port to FP4 or FP8 without accuracy losses?
-
Real-world throughput under diverse workloads: Benchmarks are promising, but ecosystem workloads vary: sparse attention, multimodal, or retrieval-augmented flows may tell a different story.
-
Supply, yield, and deployment cadence: Producing cutting-edge 3nm silicon is challenging; Microsoft must scale manufacturing and integrate chips across many datacenters.
Enterprises should evaluate Maia 200 with careful benchmarking on their own workloads rather than relying only on vendor claims.
Conclusion — when the headline reads “Microsoft Unveils Maia 200”
When Microsoft unveils Maia 200, it stakes a claim in the inference economics race: a targeted accelerator for token generation, higher memory bandwidth, and an emphasis on performance per dollar. For Azure users, Maia 200 promises attractive new options to lower inference costs and improve user-facing service performance. For the AI hardware landscape, it adds competitive pressure that should benefit customers through better price/performance and broader choice.
If you run inference at scale, the next steps are straightforward: start testing quantized models, follow Microsoft’s SDK releases, and benchmark your workloads in Azure regions where Maia 200 is available. The era of specialized inference silicon is here — and Microsoft Unveils Maia 200 may be one of the more consequential steps in how cloud providers monetize and optimize LLM services going forward.
For More Blogs = Click here
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/apple-siri-overhaul-ai-chatbot/
https://bitsofall.com/what-is-clawdbot-ai-powered-robotic-worker/
How an AI Agent Chooses What to Do Under Tokens, Latency, and Tool-Call Budget Constraints

