
Microsoft Releases VibeVoice-ASR — a deep dive
By Bits of us (adapted for your tech blog)
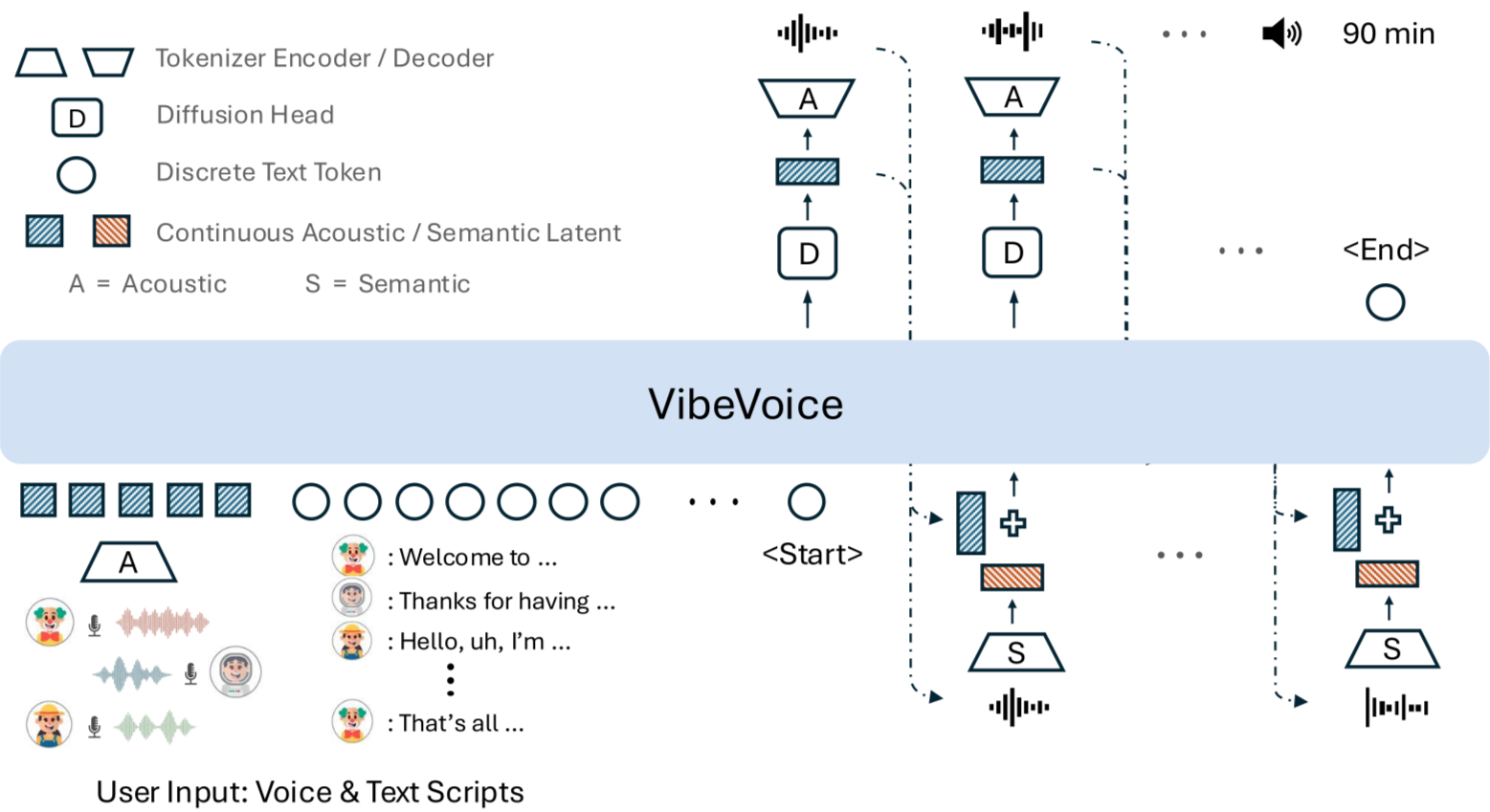
Summary (TL;DR): Microsoft has open-sourced VibeVoice-ASR, a unified automatic speech recognition model that can ingest up to 60 minutes of continuous audio in a single pass (within a 64K token context), and return structured transcripts that include who spoke, when they spoke (timestamps), and what they said — all in one inference. It also supports user-provided/custom hotwords and is part of the broader VibeVoice family on GitHub and Hugging Face.
Why this release matters
For years, long-form transcription (meetings, podcasts, lectures) has been hamstrung by segmented processing: audio is chopped into short chunks, transcribed independently, then stitched together with separate diarization and alignment steps. That pipeline works, but it loses global context (speaker identity drift, inconsistent punctuation, topic drift) and forces lots of engineering around alignment and recombination.
VibeVoice-ASR takes a different approach: it accepts a very long, continuous record as one input and maintains a global session representation across the entire hour. That design allows the model to keep track of speaker identity, topic continuity, and contextually rare words (with help from hotwords) across an extended conversation — which is exactly the scenario where pipeline approaches break down.
What VibeVoice-ASR actually does (feature list)
-
60-minute single-pass processing: The model accepts up to an hour of continuous audio and operates within a large token budget (reported at a 64K token context), avoiding repeated resets of contextual memory. This is the headline capability.
-
Unified output: ASR + diarization + timestamps: Rather than running speech-to-text, diarization, and timestamping separately, VibeVoice-ASR jointly produces a structured transcript that encodes Who (speaker), When (timestamps), and What (content) in a single inference. This simplifies pipelines and reduces downstream reconciliation work.
-
Customized hotwords / user context injection: You can provide domain specific names, product terms, acronyms, or other rare tokens as hotwords at inference time so the model is biased to recognize them correctly without retraining. This is particularly useful for enterprise jargon or brand names.
-
Open-source release and demo availability: Microsoft published VibeVoice in a public repository and provided model weights and a playground/demo on Hugging Face, enabling experimentation and integration by researchers and engineers. The repo and model are available under permissive terms, with examples and a playground to try the model.

Under the hood — architecture and design choices
Microsoft’s VibeVoice family blends techniques from continuous tokenization, large context LLM reasoning, and diffusion-style acoustic heads (a design used primarily in their VibeVoice TTS description). In short:
-
Continuous speech tokenizers run at lower frame rates (reported at ~7.5 Hz) to convert long audio into a manageable continuous token stream.
-
Large context LLM reasoning is used to interpret dialogue, maintain speaker and topic context, and decide content structure (i.e., who said what, and how to summarize or punctuate).
-
Diffusion-style acoustic heads (described in the overall VibeVoice design) are part of the family’s approach for generating detailed acoustic outputs in TTS; for ASR the framework emphasizes retaining acoustic and semantic detail across long spans.
The practical effect is that the model maintains a single global session embedding rather than repeatedly resetting its “memory” every few seconds. That allows it to do tasks that previously required multiple components (e.g., diarization + ASR) in one go.
How VibeVoice-ASR compares to existing solutions
-
Vs. segmented pipeline (classic ASR + diarization): The classic pipeline chops audio and runs separate modules; it’s reliable and efficient for short segments but loses long-range context and requires careful engineering to merge outputs. VibeVoice-ASR’s single-pass approach preserves context and simplifies the stack, at the cost of higher memory/context requirements.
-
Vs. Whisper-style models and smaller offline ASR: Whisper and similar models are excellent for general transcription tasks and are robust, but many are optimized for shorter inputs or require segmentation for long recordings. VibeVoice-ASR’s distinct advantage is explicit single-pass hour-long support and integrated diarization/timestamps.
-
Vs. commercial cloud ASR offerings: Cloud vendors often stitch multiple services (ASR + diarization + enrichment). VibeVoice-ASR’s open release offers a transparent, self-hostable alternative for teams who want on-premise or offline processing with long-form fidelity — though deploying it will require substantial memory and compute depending on the model size.
Practical considerations: sizes, latency, and compute
The VibeVoice family lists different model artifacts (for example, VibeVoice-ASR-7B on Hugging Face and other TTS/realtime models). Larger models offer better fidelity but need more RAM and inference resources. Running long continuous contexts (64K tokens) naturally increases memory usage: single-pass hour-long inputs will demand either large GPU memory or chunked inference strategies that still preserve the global context (via memory streaming or specialized runtime). Microsoft hints that VibeVoice is positioned to take advantage of emerging “AI-native” hardware and memory systems that make huge contexts practical.
Latency: Real-time use cases (live transcription) will depend on model size and runtime optimization. Microsoft already has a VibeVoice-Realtime TTS model intended for streaming; for ASR, if you need sub-second live recognition you may prefer lighter or specialized streaming models. For batch processing of long recordings (e.g., podcast archives, recorded lectures), VibeVoice-ASR’s one-pass design is ideal even with higher per-job compute.
Use cases — where this shines
-
Podcasts & long interviews: Maintain speaker identity and context across long episodes; generate show notes with correct timestamps and speaker labels.
-
Enterprise meeting capture: Hour-long meetings often jump topics and speakers; VibeVoice-ASR reduces diarization errors and produces structured minutes in a single run.
-
Lectures & educational content: Professors or multi-segment lectures that run an hour or more benefit from consistent terminology recognition (especially with hotwords for course terms).
-
Call center analytics (recorded sessions): Post-hoc analytics across long calls — including speaker turns, topic changes, and keyword spotting — are simplified. Hotwords help flag product IDs or policy names.
-
Media archiving & search: Large audio archives can be indexed with consistent, timestamped transcripts that preserve speaker continuity.
Early feedback & limitations
Community tests and discussions are already surfacing tradeoffs:
-
Accuracy is promising but not perfect: Early community runs report strong accuracy in many languages and domains (some users report ~91% in specific tests), but performance varies with language, audio quality, and polyphonic name pronunciations. Hotwords mitigate some errors.
-
Diarization edge cases: Very brief speaker interjections (<1s) inside longer sentences can still be tricky for the diarization component in some scenarios; tuning inference parameters can help.
-
Compute & memory: An hour-long single-pass requires substantial context capacity and memory — not all teams can run the largest artifacts locally without specialized hardware or batching strategies.
-
Language support & coverage: The repo and model pages show experiments and demos, but full multilingual coverage and per-language benchmarks will be evaluated by the community over time. Early user reports show cross-language potential but with variable results.
How to try VibeVoice-ASR today
Microsoft has published the VibeVoice repo and model artifacts with examples and a Playground demo on Hugging Face. Practical steps:
-
Visit the GitHub repo (
microsoft/VibeVoice) for the code, docs, and sample scripts. -
Try the Hugging Face model page (
microsoft/VibeVoice-ASR) for a quick demo and to download model weights. The page includes a live playground and instructions to run locally. -
Use Customized Hotwords: Follow the repo’s examples for injecting domain tokens at inference time if you expect brand or technical terms to appear frequently.
-
Benchmark on your audio: Run a small, representative sample from your target domain (podcast, meeting recordings) to estimate accuracy and resource needs before full deployment. Community forums and the model’s discussions are helpful for tuning tips.
Responsible use and ethical considerations
Open-sourcing a powerful ASR that can transcribe hour-long audio raises legitimate privacy and misuse concerns:
-
Consent & legality: Transcribing conversations without consent can be illegal or unethical; always follow local laws and company policies.
-
Deepfake / surveillance risk: High-fidelity transcripts can enable misuse (e.g., targeted harassment, surveillance); responsible release needs monitoring, documented terms, and safety controls. Microsoft’s prior VibeVoice work has included responsible-use caveats and occasional access gating when misuse risk is high — watch the project page for guidance.
-
Data handling & storage: When processing sensitive audio (medical conversations, legal depositions), apply strong data governance: encryption at rest/in transit, access controls, retention policies, and anonymization where appropriate.
-
Bias & fairness: ASR systems historically show uneven performance across accents, dialects, and speaker demographics. Long-form models should be tested broadly and release notes should call out known gaps. Community benchmarks will help expose and remedy disparities.
Realistic adoption roadmap for teams
If you’re evaluating VibeVoice-ASR for production:
-
Pilot phase (1–2 weeks): Run the model on representative timestamps (no PII) to measure WER (word error rate), diarization accuracy, and compute/time costs. Use hotwords for domain terms.
-
Integration phase (2–6 weeks): Build ingestion pipelines, add automated quality checks, link transcripts to downstream systems (search, analytics, note generation). Decide whether to host on-prem or in cloud GPU instances.
-
Scale & governance (ongoing): Implement monitoring for transcription quality drift, define data retention and consent controls, and document acceptable use policies. Iterate on hotword lists and inference tuning.
The bigger picture — long contexts and the future of voice AI
VibeVoice-ASR is part of a broader trend: increasing context windows + LLM reasoning applied to audio. As memory systems and AI-native hardware mature, models that hold long sessions, reason about them, and produce structured outputs will become the norm for many enterprise and creative workflows. That opens exciting possibilities: automated production notes, meeting summaries that preserve nuance, live closed-captioning with speaker IDs, and searchable audio archives — but it also raises questions about scaling, bias, and governance that the community must tackle together.
Conclusion
Microsoft’s open-sourcing of VibeVoice-ASR is an important milestone for long-form speech recognition. By moving away from chopped pipelines and toward a single-pass, context-retaining approach, the model simplifies engineering and unlocks richer outputs (Who/When/What) for hour-long audio. Early community feedback is promising, and the availability of demos and code means researchers and engineers can experiment immediately. However, real-world adoption will require attention to compute costs, careful benchmarking across languages and accents, and rigorous privacy and fairness safeguards.
If you run a podcast network, product team that records long customer calls, or an education platform with hour-long lectures — this is one of the models to test in 2026.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/vercel-releases-agent-skills-ai-coding/
https://bitsofall.com/salesforce-ai-fofpred-forecasting/

