
Xiaomi Releases MiMo-Audio: A New Era for Speech Large Models
On September 19-20, 2025, Xiaomi made waves in the AI community by open-sourcing MiMo-Audio, a 7-billion-parameter (7B) audio-language model trained on over 100 million hours of audio data. MarkTechPost+2高效码农+2 This model blends speech and text modalities in novel ways, aiming to deliver few-shot generalization in speech tasks, voice conversion, style transfer, and more—all with high fidelity. MarkTechPost+2Aibase+2
This article explores what MiMo-Audio is, how it’s built, what problems it addresses, its performance, potential applications and implications, and where it might struggle or need further work.
What Is MiMo-Audio?
MiMo-Audio (sometimes called Xiaomi-MiMo-Audio) is Xiaomi’s native end-to-end speech large model, open-sourced under permissive licensing (Apache 2.0). 高效码农+3Aibase+3Hugging Face+3
Key high-level features:
-
Size: ~7B parameters for the main backbone. There are two checkpoints: Base and Instruct (instruction tuned). 高效码农+1
-
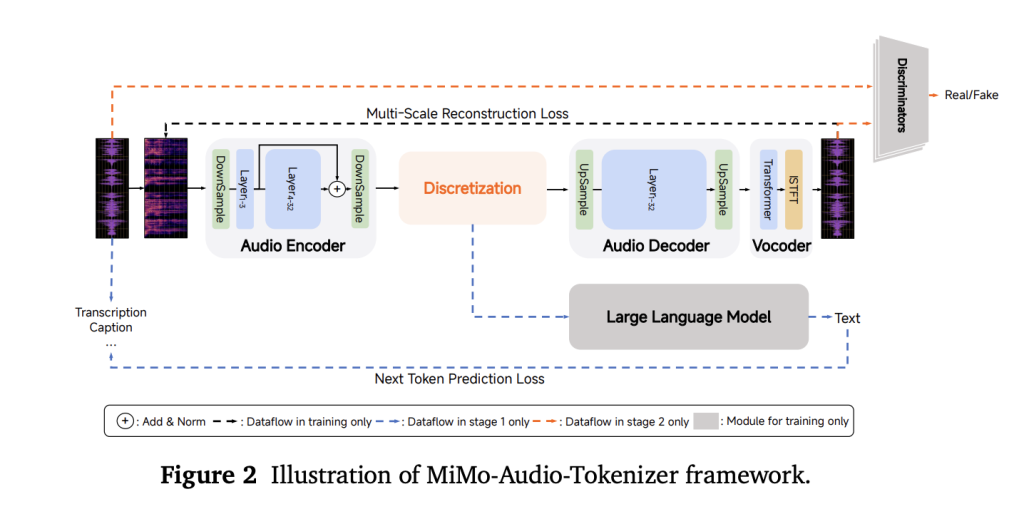
Tokenization & Audio Representation: It uses a custom tokenizer built via Residual Vector Quantization (RVQ) to discretize speech. This tokenizer works at 25 Hz and uses 8 RVQ codebooks/layers, which gives ~200 tokens per second. MarkTechPost+2高效码农+2
-
Data Scale: The model is trained on 100+ million hours of raw audio, drawn from public sources—podcasts, audiobooks, news, live streams, etc. 高效码农+1
-
Training Phases: Two main phases. First, an “understanding” stage focusing on aligning audio and text (but without audio generation). Second, a joint stage (“understanding + generation”) where the model learns to continue speech, perform speech‐to-text, text-to-speech, instruction following etc. 高效码农+1

Architectural Innovations
MiMo-Audio isn’t just a bigger model—it introduces several innovations that make this kind of audio/text integration and speech fidelity possible:
-
RVQ Tokenizer at High Fidelity
The use of residual vector quantization (RVQ) with 8 layers means the tokenizer preserves a lot of acoustic details: speaker identity, prosody, timbre, etc. The design is to make sure it is not overly lossy while still making the audio manageable for modeling. MarkTechPost+1 -
Patchification / Sequence Compression
Raw audio at 25 Hz would be a very long token sequence, which would make training and inference costly. MiMo-Audio addresses this by grouping (packing) four timesteps into one “patch” for input to the language model, so the LM sees a compressed representation at ~6.25 Hz. Then there is a “patch decoder” that reconstructs the full 25 Hz RVQ code stream for generation. MarkTechPost+1 -
Unified Next-Token Objective
Instead of having separate heads for tasks like speech-to-text (ASR), text-to-speech (TTS), voice conversion, etc., MiMo-Audio uses a single unified objective: predicting the next token in a stream that interleaves speech tokens and text tokens. This reduces architectural complexity and helps with generalization. MarkTechPost+1 -
Delayed RVQ Decoding
To maintain generation quality and respect the dependencies among layers in RVQ, the patch decoder uses a delayed multi-layer generation scheme: the different codebook layers are predicted at staggered timesteps. This helps in better quality synthesis, maintaining consistency of features like speaker identity. MarkTechPost -
Emergence & Few-Shot Behavior
By scaling data (100M+ h), Xiaomi claims the model exhibits few-shot behavior: tasks that were not explicitly trained (or only trained weakly) are handled well via in-context learning. This is analogous to what GPT-3 did for text. Aibase+1 -
Open Ecosystem Components
Xiaomi has released everything needed for experimentation: the base and instruct checkpoints, the tokenizer, an evaluation toolkit (called MiMo-Audio-Eval), technical report, and public demos. This openness is intended to accelerate research. MarkTechPost+2Aibase+2
What Problems MiMo-Audio Tries to Solve
MiMo-Audio addresses or improves on several limitations in existing speech / voice AI:
-
Task-Specific Models: Traditionally, you’d have separate models for speech-to-text, speech synthesis, voice cloning, etc. MiMo-Audio aims to reduce the need for separate architectures or separate heavy fine-tuning: many tasks can be done few-shot or with instruction tuning. 高效码农+1
-
Lossy Audio Representations: Many existing audio models use lossy tokenizers or representations that discard prosody, speaker identity, or timbre. MiMo-Audio tries to preserve those via RVQ across many codebooks, along with sufficient frame rate. MarkTechPost+1
-
Modality Gaps: The gap between performance on text tasks and speech tasks is often large. By interleaving text and audio tokens and using unified objectives, MiMo-Audio aims to shrink this gap. MarkTechPost+1
-
Generalization: Many speech models do well on benchmarks they were explicitly trained on but fail to generalize to new voice styles, accents, emotions, or new tasks. Xiaomi is pushing for few-shot generalization in speech tasks. 高效码农+1

Performance Benchmarks & Capabilities
According to Xiaomi’s reporting, MiMo-Audio shows strong results in several benchmark suites and capabilities. Some of the highlights:
-
Speech Understanding / Speech Intelligence Benchmarks
MiMo-Audio performs very well on SpeechMMLU and MMAU benchmarks, which test understanding and reasoning in speech settings. The model is claimed to reduce the modality gap (the difference in performance between text-only and speech tasks). MarkTechPost+1 -
Audio Generalization Benchmarks
It is also evaluated on general audio understanding tasks: sound classification, music, etc. Xiaomi reports strong scores. MarkTechPost -
Few-Shot & Zero-Shot Tasks
Capabilities reported include voice conversion, emotion transfer, speech continuation (i.e. given a prompt audio, continue with same voice/tone/acoustic style), denoising, speed change, style transfer. Some speech translation (speech-in, speech-out) works even with few (e.g. up to 16) examples. 高效码农 -
ASR (Automatic Speech Recognition)
On standard ASR test sets, the model shows competitive Word Error Rates (WER) out of the box in some cases. 高效码农 -
Instruction-Tuned Model (“Instruct” checkpoint)
The instruct version supports “thinking modes” (switch between “non-thinking” and “thinking” modes via prompt), styles (emotional tone, speed, loudness, etc.), dialog, etc. Aibase+1
Strengths & Innovations
From what has been published and observed so far, the major strengths of MiMo-Audio include:
-
High Audio Fidelity: Because of RVQ tokenization, delayed decoding, many codebooks, and high frame rate (25 Hz) preserved, the generated audio maintains prosody, speaker identity, timbre, and acoustic nuance.
-
Unified Model for Many Tasks: Instead of needing many different specialized models, MiMo-Audio can handle speech-to-text, text-to-speech, voice conversion, continuation, translation etc. This simplifies deployment and research.
-
Open Source & Ecosystem: Xiaomi has released all relevant components (tokenizer, base/instruct checkpoints, evaluation toolkit, demos). This fosters reproducibility and further innovation. Researchers and developers can build upon it. Hugging Face+2Aibase+2
-
Few-Shot Generalization: One of the more exciting claims is that with enough data and the right architecture, speech models can begin to show emergent properties similar to those seen in large text LMs: being able to adapt to new tasks with limited examples. This lowers the barrier to new speech-based applications. 高效码农+1
-
Efficiency in Sequence Processing: The patchifier and decoder architecture helps keep the sequence lengths manageable for the LLM part, reducing compute cost while preserving acoustic detail. This enables training and inference more practically. MarkTechPost+1
Limitations, Challenges, and Open Questions
While MiMo-Audio is a major step forward, there are some limitations, caveats, and areas that may require more work.
-
Size & Computational Requirements
Even though 7B is not huge in the scale of LLMs nowadays, dealing with speech plus audio decoding, RVQ, etc., is expensive. Inference latency, memory usage, and compute cost for real-time or low-resource environments might be challenging. -
Languages and Accents
Most of the training data is Chinese and English (the article mentions a 95% Chinese/English filter for language-id) with automatic filtering. Other languages or accents might have less representation, which can degrade performance in those settings. 高效码农 -
Data Bias, Noise, and Labeling
Given the scale (100+ million hours), much of the data is likely noisy, with automatic segmenting, speaker diarization, language identification, etc. While these enable scale, they can introduce bias or degrade performance in edge cases. -
Quality vs. Real-World Use
Benchmarks are a good indicator, but real-world deployment brings issues like background noise, varying microphones, compressed audio, adversarial conditions, or really long audio segments. How robust is MiMo-Audio in such contexts remains to be seen. -
Ethical, Privacy, and Misuse Risks
As with any powerful voice model, risks include voice cloning, deep fake audio, impersonation, unauthorized use of voice styles, etc. Also licensing of the data used, speaker consent, etc., are concerns in large-scale speech model training. -
Open-Source Support and Usability
While the model and tools are released, effective usage (especially in non-Chinese/English contexts) will depend on documentation, tutorials, hardware availability, and community contributions. Also, quantization and optimizing models for deployment matter a lot.
Potential Applications
The capabilities MiMo-Audio brings open up many possible applications. Here are some plausible areas:
-
Voice Assistants and Conversational AI
More natural and flexible assistants that can understand speech, respond in speech with style/emotion, switch voices or tones, etc. Could be embedded in devices, smart speakers, phones. -
Content Creation & Media
Podcasters, YouTubers, game developers, etc., could use it for voice cloning, voice style transfer, dubbing, translations, narrations in different tones, background noise removal, etc. -
Accessibility
Helping people with hearing or speech impairment via improved speech recognition, voice synthesis in personalized voices, or assistive interfaces that can understand diverse speech styles. -
Language Learning
Tools to help learners hear correct pronunciation, mimic accent, get translations, or practice speaking and get feedback. -
Telecommunications & Call Centers
Transcribing, translating, summarizing speech, or even generating responses in calls. Also, improving customer service bots with voice. -
Localization & Translation
Speech-to-speech translation preserving speaker style, emotion, etc., which is very valuable in media, globalization, and cross-lingual communication. -
Research & Innovation
The open-source nature allows academic and industrial researchers to experiment, push the performance further, adapt to new domains (e.g. medical, law, etc.), and contribute to the general field of speech AI.

Comparison to Other Models
To appreciate MiMo-Audio’s place, it helps to compare it to other recent speech and multimodal models:
-
There are many speech models specializing in ASR (speech-to-text) or Text-to-Speech (TTS), but fewer that combine multiple speech tasks + text + speech generation in one unified model with few-shot generalization.
-
Closed-source models (from Google, OpenAI, etc.) have strong performance, but often are limited in transparency, licensing, or accessibility. Xiaomi claims MiMo-Audio outperforms some closed-source models (e.g. Gemini-2.5-Flash, OpenAI’s audio preview) on certain benchmarks. Aibase+1
-
Some existing open-source models may have trade-offs: simpler tokenization, fewer audio tokens, less richness of style/emotion, or needing fine-tuning for each task. MiMo-Audio seems to push forward on fidelity and generalization.
Impact & Implications
What does the release of MiMo-Audio mean more broadly in AI, speech tech, and society?
-
Acceleration of Audio/Voice Research
Because Xiaomi is open-sourcing not just a model but the whole ecosystem (tokenizer, evaluation, instructions), many barriers are lowered. Researchers who didn’t have access to huge proprietary datasets or specialized hardware can experiment, reproduce, and build on this. This might spur many derivative models, improvements, or domain-specialized voice LMs. -
Potential Platform & Service Innovation
Companies can integrate or build products using MiMo-Audio as a foundation: improved voice assistants, new content tools, etc. Open source means lower cost of entry for startups or smaller players. -
Ethical & Regulatory Discussions
As voice generation and translation, voice cloning become more powerful, there will likely be increased discussions about misuse, consent, speaker rights, deepfake detection, privacy policies etc. MiMo-Audio adds more urgency to these discussions. -
Globalization and Multilingual Breakthroughs
If MiMo-Audio can be adapted to many languages, dialects, and speech styles, it could help reduce language barriers. But it will require effort to expand data, fine-tune or adapt to languages outside its initial focus. -
Shift in How Speech Models Are Built
The unified next-token objective, interleaved speech+text tokens, patchification and preserving high acoustic detail—all may set a new design paradigm for future speech large models.
Technical Details (Deep Dive)
For those interested, here are some more detailed technical aspects of MiMo-Audio based on what’s published.
| Component | Description |
|---|---|
| Tokenizer | Uses RVQ with 8 codebooks; operates at 25 Hz. Turns 24 kHz waveforms into discrete tokens (~200 tokens/sec). Trained with joint losses: audio reconstruction + alignment/semantic token losses. 高效码农+1 |
| Patch Encoder | Packs 4 timesteps into a patch → compressing input to ~6.25 Hz representation for LM input. Helps reduce sequence length. MarkTechPost+1 |
| 7B LM Backbone | Processes both text tokens and patch embeddings (speech) under a unified next-token prediction objective. No separate heads during the main training. MarkTechPost+1 |
| Patch Decoder | During generation, recovers full-rate audio tokens from the lower-rate patches. Uses delayed multi-layer RVQ decoding to preserve quality across codebook layers. MarkTechPost |
| Training Phases | Stage 1: Understanding – focuses on text/audio alignment but no audio generation. Stage 2: Joint – enables speech continuation, generation, multiple tasks. Instruction tuning is done later. 高效码农+1 |
| Data | 100M+ hours of audio, from varied sources: podcasts, audiobooks, news, etc. Language ID filters (mostly Chinese & English). Data presumably filtered automatically, with speaker diarization. 高效码农+1 |
| Evaluation & Benchmarks | SpeechMMLU, MMAU, Big Bench Audio, ASR benchmarks like LibriSpeech, AIShell etc. The model reportedly beats or matches several closed-source models in certain tasks. Aibase+1 |

What To Watch Next
Here are some aspects to monitor in the coming months/years, for MiMo-Audio and its successors:
-
Multilingual & Low-Resource Languages: How well it can adapt or be fine-tuned to languages with less data, accents, dialects outside Chinese/English.
-
Real-World Robustness: Performance under noisy, reverberant, low-quality recording conditions; over phone lines; with compression; in hands-free settings etc.
-
Latency and Deployment Efficiency: Can the model be optimized (quantized, pruned, etc.) to run on edge devices (phones, smart speakers) or in real-time? How fast can speech generation/translation/continuation be made in practice?
-
Ethics, Voice Rights, and Deepfake Detection: Policies, technical safeguards, watermarking, consent, attribution, etc.
-
Further Emergence: As more data is fed, and instruction-tuned variants are refined, what new or surprising capabilities emerge? Better translation, style adoption, mixed modalities, etc.
-
Community Contributions: Because it’s open source, community will likely add features — more languages, dialects; fine-tuned versions for specific domains (medical, law, entertainment); optimized toolkits; better inference pipelines.
Conclusion
Xiaomi’s release of MiMo-Audio marks an important milestone in speech AI. It combines scale, fidelity, and architectural design in a way that seems to bring many of the desirable properties of large text-language models into the speech domain: few-shot generalization, unified models, rich audio, multiple tasks from the same system.
It is not perfect—for certain languages, environments, or applications, limitations remain—but it provides a strong foundation for future speech models, and its open sourcing will allow much wider experimentation and innovation. As voice-driven interaction becomes more and more central (in assistants, AR/VR, content creation, translation, etc.), models like MiMo-Audio could help push what’s possible forward substantially.
For quick updates, follow our whatsapp –
https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/https-yourblog-com-building-ai-agents-is-5-ai-and-100-software-engineering/
https://bitsofall.com/https-yourblog-com-a-coding-guide-to-implement-zarr-for-large-scale-data/
Top Computer Vision (CV) Blogs & News Websites — 2025 edition
H Company Releases Holo1.5: Redefining the Future of Holographic Intelligence

