
Large Language Models (LLMs): The Engines Behind Modern AI
Introduction
In the past decade, the world has witnessed remarkable breakthroughs in artificial intelligence (AI). At the center of these advancements are Large Language Models (LLMs)—powerful systems capable of understanding, generating, and reasoning with human language. From writing emails and generating code to answering questions and powering chatbots, LLMs have become the backbone of modern AI applications.
This article explores what LLMs are, how they work, their evolution, applications, challenges, and the future possibilities they unlock. By the end, you’ll gain a deep understanding of why LLMs are often called the “engines of generative AI.”
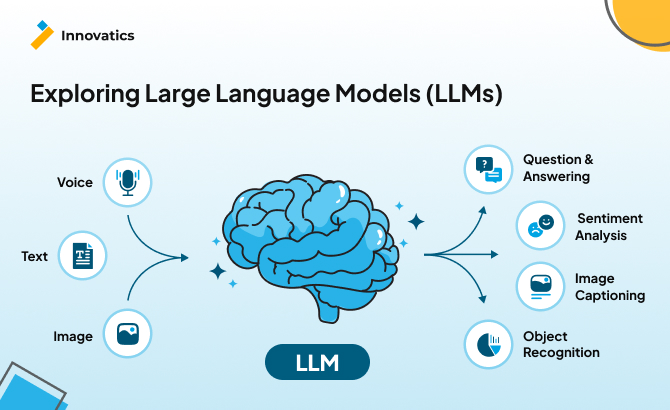
What Are Large Language Models?
Large Language Models (LLMs) are a class of machine learning models designed to process and generate natural language text. They are trained on vast amounts of data—books, articles, websites, code repositories, and other forms of text—to learn the structure, grammar, semantics, and nuances of human language.
Some well-known LLMs include:
-
GPT series (OpenAI) – including GPT-3, GPT-4, and GPT-5.
-
LLaMA (Meta) – lightweight models optimized for efficiency.
-
PaLM (Google) – Pathways Language Model trained for scale.
-
Claude (Anthropic) – designed with an emphasis on alignment and safety.
At their core, LLMs are based on transformer architecture, which allows them to capture long-range dependencies in text and generate coherent responses. Unlike traditional models limited to short contexts, transformers enable LLMs to process thousands of tokens at once.
How Do Large Language Models Work?
Understanding how LLMs work requires looking at a few key concepts:
1. Training Data
LLMs are trained on massive corpora of text from the internet, books, research papers, and codebases. The diversity of data allows them to develop broad general knowledge.
2. Tokenization
Before training, text is broken into smaller units called tokens (words, subwords, or characters). For example:
-
Sentence: “Artificial intelligence is amazing.”
-
Tokens: [“Artificial”, “intelligence”, “is”, “amazing”, “.”]
The model learns statistical relationships between these tokens.
3. Neural Architecture (Transformers)
Introduced by Vaswani et al. in 2017, the transformer model revolutionized natural language processing. It uses mechanisms like:
-
Self-attention – allows the model to weigh the importance of each token relative to others.
-
Positional encoding – adds order information to tokens, since word order matters.
-
Layers of computation – stacked networks process representations of text.
4. Pre-training and Fine-tuning
-
Pre-training: The model learns general patterns of language by predicting the next token in billions of examples.
-
Fine-tuning: Developers adapt the model to specific tasks (e.g., coding, legal advice, or medical reasoning).
5. Inference
When you ask ChatGPT a question, the model uses its learned parameters to predict the most likely next word (token by token) until it forms a full response.
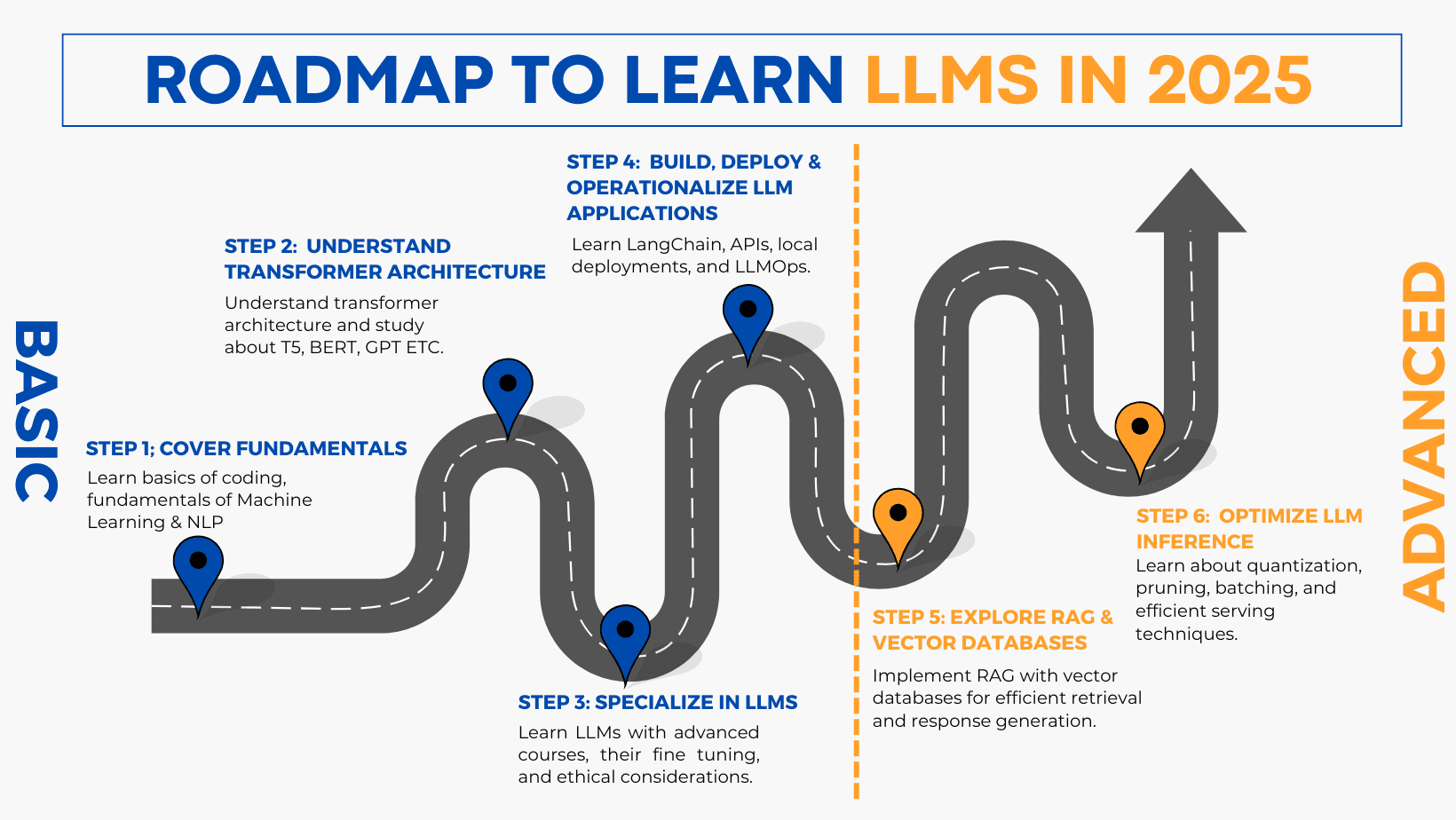
Evolution of LLMs
The journey of LLMs can be divided into several phases:
-
Early NLP Models – Before 2017, recurrent neural networks (RNNs) and LSTMs dominated natural language processing, but they struggled with long contexts.
-
Transformer Revolution (2017) – The paper “Attention Is All You Need” introduced transformers, which became the foundation of all modern LLMs.
-
GPT Era (2018–2020) – OpenAI’s GPT series demonstrated that scaling up data and parameters drastically improved performance. GPT-3, with 175 billion parameters, set a new benchmark in 2020.
-
Competition and Innovation (2021–2024) – Google (PaLM), Meta (LLaMA), Anthropic (Claude), and others released competing models, each focusing on scale, efficiency, or alignment.
-
Multi-modal LLMs (2024–2025) – Recent models can process not only text but also images, audio, and video. This evolution bridges the gap between language and other forms of data.
Applications of LLMs
LLMs are widely deployed across industries. Some of the most impactful applications include:
1. Conversational AI
Chatbots like ChatGPT, Claude, and Gemini power customer service, virtual assistants, and personal productivity tools.
2. Content Creation
LLMs generate articles, blogs, social media posts, ad copy, and even poetry. Writers now use them as co-creators to save time.
3. Programming Assistance
Tools like GitHub Copilot use LLMs to auto-complete code, suggest fixes, and accelerate software development.
4. Education
LLMs serve as tutors, providing personalized learning experiences, explanations, and practice questions for students.
5. Healthcare
They assist in medical research, help doctors analyze reports, and generate patient-friendly summaries of diagnoses.
6. Business Intelligence
LLMs summarize reports, analyze trends, and generate insights from unstructured data.
7. Scientific Research
By reading millions of papers, LLMs suggest hypotheses, summarize findings, and help researchers accelerate discovery.
Benefits of LLMs
-
Scalability – Once trained, an LLM can serve millions of users.
-
Versatility – One model can perform multiple tasks (translation, summarization, reasoning).
-
Productivity Boost – They automate repetitive tasks, freeing humans for creative or strategic work.
-
Accessibility – LLMs democratize access to knowledge, making expertise more widely available.

Challenges and Limitations
While powerful, LLMs face several issues:
1. Hallucinations
LLMs sometimes generate factually incorrect information with high confidence. For example, citing nonexistent studies.
2. Bias and Fairness
Since they learn from human-generated data, LLMs inherit biases related to gender, race, and culture.
3. Cost and Energy
Training large models requires enormous computational resources, raising concerns about sustainability.
4. Data Privacy
LLMs trained on internet-scale data may inadvertently expose sensitive information.
5. Alignment and Safety
Ensuring models act in line with human values and avoid harmful behavior is an ongoing challenge.
The Future of LLMs
The future direction of LLMs involves both technical and ethical dimensions:
1. Smaller, More Efficient Models
Efforts like distillation and quantization aim to make LLMs smaller and more energy-efficient without losing capabilities.
2. Domain-Specific LLMs
Instead of general-purpose models, industries will use specialized models fine-tuned for law, medicine, or finance.
3. Integration with Multi-Modal AI
Future LLMs won’t just handle text but seamlessly integrate vision, audio, and even robotics control.
4. Explainability
Research into interpretability will help users understand why an LLM gives a certain response.
5. Stronger Ethical Frameworks
Governments and companies are working on regulations to ensure responsible AI deployment.
Ethical Considerations
-
Misinformation – LLMs can be misused to generate fake news.
-
Job Displacement – Automation of content and coding raises concerns about employment.
-
Ownership of Data – Should creators be compensated if their work is used to train LLMs?
-
Control and Governance – Who should regulate powerful AI systems?

Conclusion
Large Language Models represent one of the most transformative technologies of the 21st century. They’ve already redefined how we work, learn, and communicate. From powering chatbots to assisting in research, their potential seems limitless.
However, alongside their promise comes responsibility. Society must address the challenges of bias, misinformation, and ethical use to ensure these models benefit everyone.
As we move toward an AI-driven future, LLMs will remain at the core—continuing to shape the digital world and, by extension, human progress.
The Discovery of New Ebola Drug Targets Using ML-Powered Imaging
Faster Methods for Chemical Property Prediction (ChemXploreML)

