
Google’s Gemini 3 Pro turns sparse MoE and 1M-token context into a practical engine for multimodal agentic workloads
Executive summary
Google’s Gemini 3 Pro is being positioned as a step change in practical agentic AI: it combines a sparse Mixture-of-Experts (MoE) backbone with a native multimodal stack (text, image, audio, video, code) and a 1 million-token context window. The combination addresses two pain points that have constrained previous agent systems — scale of model capacity without linear compute cost (thanks to sparse MoE routing) and long memory / long-document reasoning (thanks to the 1M token context). Together these features make it feasible to build agents that can ingest entire codebases, long legal contracts, video tutorials, and multi-file datasets and then plan, act, and maintain context across long, multi-step tasks. blog.google+1
Why the architecture matters: sparse MoE + huge context
Two architectural advances are the headline:
-
Sparse Mixture-of-Experts (MoE): An MoE model contains many specialist sub-modules (“experts”) but activates only a small subset per token or per token group. That sparsity allows total parameter count — the model’s capacity — to scale enormously without a proportional increase in compute for each inference step. In practice, a sparse MoE can give you the modelling power of an extremely large model while keeping latency and serving costs closer to a much smaller dense model. This trade-off is central to Gemini 3 Pro’s design. Google DeepMind
-
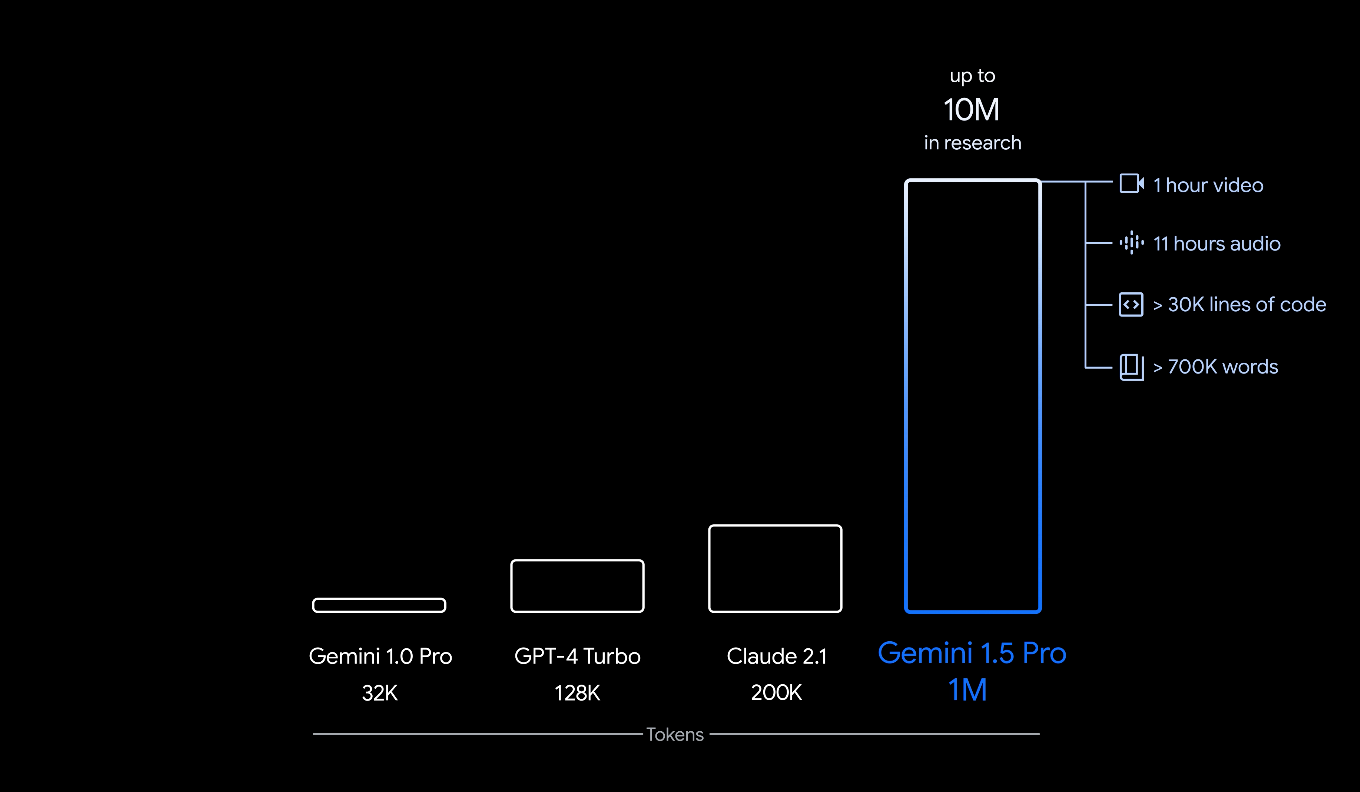
1,000,000-token context window: This is not just a larger sliding window — it changes the class of problems the model can address. Instead of stateless prompts truncated at 4k–64k tokens, Gemini 3 Pro can hold entire books, long video transcripts, multi-module codebases, and composite multimodal inputs in memory at once. That gives agents the ability to (a) plan over very long horizons, (b) maintain persistent state across many tool calls, and (c) reason about interactions across long documents and multimedia inputs. Google’s docs and product pages emphasize the model’s ability to tackle enterprise-scale, long-running workflows because of this context size. Google Cloud Documentation+1
These two features are synergistic: huge capacity without prohibitive compute cost (via sparse MoE) makes it possible to serve a model that actually benefits from a 1M token context in production settings.

Practical gains for multimodal agents
What does this mean for real agentic workloads? Here are concrete problem classes where Gemini 3 Pro’s design pays off:
-
Long-horizon planning and execution: Agents that need to plan multi-step workflows — e.g., orchestrate a data migration that requires reading thousands of lines of config, scripts, and runbooks — now have the raw context to keep the whole plan and evidence visible during execution. That reduces error caused by context truncation and avoids brittle stepwise reconstruction of state.
-
Codebase understanding & developer assistants: When an agent can load an entire repository (files, tests, CI logs, docs) into its context, it can reason about cross-file semantics (refactors, API uses, dependency trees) instead of guessing from a few files. This reduces hallucinations in code changes and enables better automated PR generation, debugging, and patch proposals.
-
Multimodal synthesis (video + docs + chat): Agents can watch a video tutorial transcript, inspect accompanying slides / PDFs, and use code snippets — all within a single context — enabling unified multimodal question answering and step-by-step task completion that respects the original source material.
-
Long legal/financial document analysis: Law firms and finance teams can have the model ingest whole contracts, amendments, and precedents and then ask the agent to draft redlines, cross-reference clauses, or produce negotiation checklists that rely on the entire document set.
-
Persistent memory & user personalization: With a million tokens, persistent, user-specific memory (preferences, past chats, project artifacts) becomes feasible without stitching disparate short-term contexts together manually.
These use cases are not hypothetical — Google and multiple independent commentators highlight enterprise scenarios (document analysis, tool orchestration, and agentic task execution) as immediate beneficiaries of the new model. Google Cloud+1
How Gemini 3 Pro makes this practical (and not just a lab demo)
Large context and huge capacity are impressive in a paper, but production constraints (latency, cost, reliability) usually kill practical deployments. Gemini 3 Pro tries to address those constraints in several ways:
-
Selective activation via MoE: By activating only a small number of experts per token, the system avoids paying the full compute bill of a trillion-parameter model for every token. The net effect is higher representational power per unit of compute. This is exactly the trick required to make “very large but sparse” models usable for low-latency multimodal agents. Google DeepMind
-
Dynamic thinking modes and latency knobs: Google’s developer notes indicate there are different reasoning modes (e.g., “dynamic thinking” vs. constrained/low-latency modes) so developers can trade off depth of chain-of-thought-style reasoning for lower latency when needed. That flexibility is critical for agents that must sometimes respond in real time and sometimes perform long internal deliberation. Google AI for Developers
-
Tooling & integrations (Vertex AI / Enterprise): Gemini 3 Pro is surfaced via Vertex AI and Gemini Enterprise solutions, with tooling around function calling, tool orchestration, and memory management. These integrations shorten the path from model capability to operational agent. console.cloud.google.com+1
-
Multimodal token accounting & modality routing: The docs note modality-specific handling (e.g., images and PDFs may be token-counted under particular modalities). Practical agent builders will rely on these conventions and SDKs to manage uploads, pre-processing, and cost estimation — another sign this was built with productization in mind. Google Cloud Documentation
Limitations, risks, and engineering tradeoffs
No advance is free. Here are the key caveats to bear in mind when building on Gemini 3 Pro:
-
Routing quality & failure modes: Sparse MoE relies on a routing mechanism to decide which experts to activate. Poor routing can produce instability or brittle behavior (e.g., cherry-picking the wrong experts for rare inputs). Ensuring robust routing across many modalities and edge cases is an open engineering challenge.
-
Debuggability and interpretability: MoE architectures with many experts raise the bar for interpretability — which expert handled which part of the reasoning, and why? For safety-critical or audit-heavy domains, that opacity can be a problem.
-
Cost vs. dense alternatives for some workloads: Although MoE reduces per-token compute, workloads that need all experts or that require repeated multi-pass reasoning could still be expensive. For short prompt workloads, smaller dense models may remain more cost-effective.
-
Hallucination & factuality across long contexts: Holding a million tokens reduces truncation hallucinations, but it does not automatically remove hallucinations stemming from training data gaps or weak grounding. Agents still need grounding (retrieval, tool calls, human-in-the-loop checks) for high-stakes outputs.
-
Data privacy & vector leakage risks: Feeding entire proprietary codebases, contracts, or user histories into a cloud model raises data governance questions. Enterprises must think carefully about on-prem options, fine-grained access controls, and logging policies.
Several early analyses and product pages hint at these tradeoffs, and independent commentary has flagged routing and cost as two areas to watch. MarkTechPost+1
Design patterns for agent builders
If you’re building agentic systems with Gemini 3 Pro, consider these patterns:
-
Chunk + index + context-window stitching: Even with 1M tokens, chunking + semantic indexing remains useful for retrieval speed. Use the big context for final reasoning and cross-chunk synthesis rather than naïvely loading all raw data every time.
-
Tiered thinking modes: Route quick UI responses through constrained, low-latency settings. Reserve full dynamic thinking for backend processes that can take longer and use more compute.
-
Expert-aware prompting & routing hints: If routing transparency is exposed in the SDK, experiment with lightweight routing hints so that domain-specific experts are prioritized for relevant inputs (e.g., code expert for repository tasks).
-
Grounding with tools & verification layers: Always pair agent outputs with verification — unit tests for code changes, symbolic checks for finance calculations, or retrieval from authoritative documents before committing actions.
-
Hybrid on-device + cloud architecture: For sensitive data, keep retrieval, redaction, or vectorization local. Use Gemini 3 Pro as the high-level reasoner that receives sanitized or tokenized summaries when possible.
These patterns reflect the practical constraints of enterprise deployments and are compatible with Google’s announced tooling directions. console.cloud.google.com
Competitive context and benchmarks
Early benchmark reports and model-card leaks show Gemini 3 Pro performing very strongly on multi-step reasoning, coding, and multimodal benchmarks, occasionally outperforming leading contemporaries on select suites. Independent write-ups and leaked model cards have been quick to compare Gemini 3 Pro against open products and competitor closed models; results vary by benchmark and task type, but the consensus is that Gemini 3 Pro is a major step forward for agentic, multimodal workloads where long context and tool use matter. As always, benchmark claims should be evaluated against real-world tasks rather than headline scores alone. News9live+1
What this means for industry and research
-
Agentization accelerates: With practical long-context, multimodal reasoning available in a production-grade model, we should expect a wave of agentic tools that can manage long, multi-modal projects end-to-end (onboarding assistants, legal analysts, devops automators).
-
New UX paradigms: Interfaces will pivot from short Q&A to long, persistent conversations where the agent truly “remembers” and reasons with whole artifacts (videos, docs, repos).
-
Research challenges renewed: Routing, expert specialization, multimodal alignment, and interpretability become frontier research areas again — the community will race to make MoE safer, more transparent, and more robust.
-
Enterprise adoption & governance: Organizations will need new policies for long-context storage, redaction, and traceability to adopt these agents responsibly.
Final takeaway
Gemini 3 Pro is not just “bigger” — it is an attempt to rewire the practical tradeoffs that have limited agents: immense capacity (via sparse MoE) without prohibitive compute per token, and a context window so large that entire projects can be held in-memory during reasoning. That combination addresses long-standing friction points for multimodal, tool-enabled agents and makes a new class of production-grade agentic applications feasible. The model is a powerful enabler, but practical adoption will depend on careful engineering around routing, grounding, verification, and governance. If those elements are handled well, the next generation of agents will be markedly more capable, more persistent, and much closer to the kinds of long-lived assistants that teams and enterprises want today. blog.google+2Google DeepMind+2
Sources & further reading
Key sources used for this article:
-
Google product announcement and overview for Gemini 3. blog.google
-
Vertex AI / Google Cloud model pages and developer docs for Gemini 3 Pro. Google Cloud Documentation+1
-
DeepMind / Google model detail pages describing Gemini 3 Pro and its capabilities. Google DeepMind
-
Independent technical analysis and reporting on architecture and implications. MarkTechPost+1
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/focal-loss-vs-binary-cross-entropy-2025/
MBZUAI Researchers Introduce PAN — A General World Model for Interactable, Long-Horizon Simulation

