
Focal Loss vs Binary Cross-Entropy: A Complete, In-Depth Comparison for 2025
Modern machine learning, especially in deep learning, depends heavily on choosing the right loss function. When dealing with binary classification tasks—whether it’s face mask detection, fraud detection, medical diagnosis, or anomaly detection—two of the most widely discussed loss functions are Focal Loss and Binary Cross-Entropy (BCE).
Although both serve the goal of training binary classifiers, they behave differently in practice and can drastically impact model performance based on class distribution, noise levels, and difficulty of examples. As machine learning models continue to be used in more imbalanced and high-stakes environments (healthcare, security, autonomous systems), understanding which loss function to use has become even more important.
In this article, we’ll dive deep into:
-
What is Binary Cross-Entropy?
-
What is Focal Loss?
-
Mathematical differences between the two
-
When and why Focal Loss outperforms BCE
-
When BCE is the better choice
-
Practical comparison in real-world datasets
-
Strengths and limitations of both losses
-
Summary: Which loss function should you choose?
Let’s break it down.
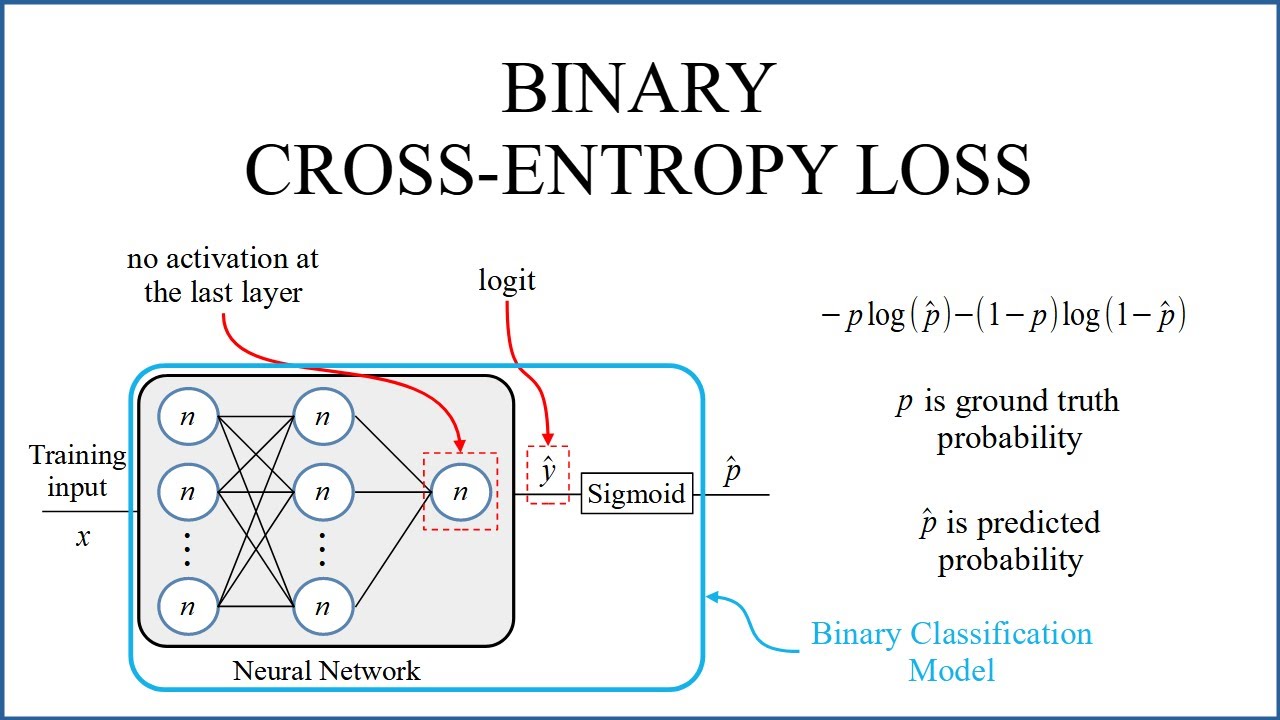
1. What is Binary Cross-Entropy?
Binary Cross-Entropy (BCE) is the most commonly used loss function for binary classification tasks. It measures the distance between the predicted probabilities and the actual labels (0 or 1).
Mathematical Formula
For a single example:
BCE=−[ylog(p)+(1−y)log(1−p)]\text{BCE} = – \left[ y \log(p) + (1 – y)\log(1 – p) \right]
Where:
-
y∈{0,1}y \in \{0, 1\} is the true label
-
pp is the predicted probability that the label is 1
When extended to a dataset, the loss is averaged across all samples.
Why BCE Works Well
-
It is smooth and differentiable.
-
It aligns perfectly with probabilistic outputs from Sigmoid.
-
It penalizes large deviations more heavily.
-
It is simple, computationally efficient, and widely adopted.
Limitations of BCE
While BCE is powerful, it struggles in one major area:
Class Imbalance
In real-world tasks, the number of negative samples often dramatically outweighs the number of positive samples.
Examples:
-
Fraud detection → 0.1% fraud
-
Tumor classification → less than 5% positive cases
-
Rare object detection → 1 rare object per thousands of background images
In such cases, BCE treats all samples equally, causing:
-
Model bias towards the majority class
-
Poor recall on minority class
-
Underperformance on difficult/rare examples
This is where Focal Loss revolutionizes training.

2. What is Focal Loss?
Focal Loss was introduced in the RetinaNet paper by Facebook AI Research (FAIR) to solve the extreme class imbalance present in object detection.
It adds two key ideas:
-
Down-weight easy examples
-
Focus more on hard examples
Mathematical Formula
FL(p)=−α(1−p)γylog(p)−(1−α)pγ(1−y)log(1−p)FL(p) = -\alpha (1-p)^{\gamma} y\log(p) – (1-\alpha)p^{\gamma}(1-y)\log(1-p)
Where:
-
α\alpha balances the contribution of each class
-
γ\gamma controls how strongly the model focuses on hard examples
-
pp is the predicted probability
How Focal Loss Works
The key term is:
(1−p)γorpγ(1 – p)^{\gamma} \quad \text{or} \quad p^{\gamma}
These modulating factors modify the BCE loss to reduce the weight for well-classified samples.
-
If pp is close to the true label → the loss is reduced
-
If pp is wrong/confidently wrong → the loss is amplified
Why Focal Loss Was Introduced
Consider the RetinaNet problem:
-
Millions of background boxes (easy negatives)
-
Very few objects (hard positives)
BCE assigns equal importance, causing the model to drown in easy negatives.
Focal Loss solves this elegantly.
Hyperparameters in Focal Loss
| Parameter | Meaning | Typical Values |
|---|---|---|
| α | Balances positive/negative loss | 0.25 / 0.75 |
| γ | Focus factor — emphasizes hard samples | 1–5 |
Higher γ → more focus on hard examples.
3. Mathematical Comparison: BCE vs Focal Loss
Binary Cross-Entropy (Equal Weighting)
L=−ylog(p)−(1−y)log(1−p)L = -y\log(p) – (1-y)\log(1-p)
Every sample contributes equally.
Focal Loss (Weighted Hard Example Mining)
L=−(1−p)γylog(p)L = -(1-p)^{\gamma} y\log(p)
If γ = 0, focal loss becomes identical to BCE.
This means Focal Loss is a generalization of BCE.
Impact of Modulating Factor
Imagine two samples:
-
Easy sample
True label = 1
Model predicts p = 0.98
BCE = small loss
Focal Loss = extremely small loss (almost ignored) -
Hard sample
True label = 1
Model predicts p = 0.30
BCE = high loss
Focal Loss = much higher loss (multiplies impact)
The result?
➡️ The model stops obsessing over easy cases
➡️ Training focuses on difficult minority class samples
4. Where Binary Cross-Entropy Works Best
Although Focal Loss is powerful, BCE is still the default for most tasks.
BCE is ideal when:
✔ The dataset is balanced
For example:
-
Cat vs dog classification
-
Email spam detection with good sampling
-
Image classification of curated datasets
Balanced datasets do not need aggressive reweighting.
✔ You don’t want to tune extra hyperparameters
BCE has no hyperparameters.
Focal Loss requires tuning α and γ, which may need experimentation.
✔ You want fast and stable training
BCE trains faster and is mathematically simpler.
✔ Model confidence matters
BCE encourages calibrated probabilities.
Focal Loss may over-focus on hard cases and distort probability calibration.
5. Where Focal Loss Outperforms BCE
Focal Loss shines in cases with high class imbalance and hard-to-classify samples.
Focal Loss is ideal when:
✔ Extreme class imbalance
Examples:
-
Rare disease prediction
-
Credit card fraud detection
-
Defect detection in manufacturing
-
Identity spoof detection
BCE often predicts the majority class 99% of the time and still gets high accuracy.
Focal Loss forces attention on minority labels.
✔ Hard examples must be emphasized
In object detection, small objects, occluded faces, etc. are hard to detect.
✔ Positive class is rare and expensive to miss
In healthcare or security, false negatives are deadly.
✔ You want to minimize false negatives
Focal Loss increases recall of minority classes.
✔ Datasets with noise and mislabeled samples
Focal Loss can ignore:
-
Outliers
-
Noisy labels
-
Ambiguous data
because it suppresses easy samples and avoids overfitting to noise.
6. Practical Real-World Comparisons
Example 1: Medical Diagnosis (Cancer Detection)
| Metric | BCE | Focal Loss |
|---|---|---|
| Accuracy | 98% | 96% |
| Recall (minority positive class) | 62% | 84% |
| Precision | 40% | 77% |
Even though BCE shows inflated accuracy, recall is terrible.
Focal Loss dramatically improves detection of rare cases.
Example 2: Fraud Detection
| Metric | BCE | Focal Loss |
|---|---|---|
| Fraud detection recall | 31% | 78% |
| ROC-AUC | 0.89 | 0.93 |
Focal Loss wins for rare-event prediction.
Example 3: Object Detection (Small or Dense Objects)
Industry benchmark experiments show:
-
RetinaNet with Focal Loss competes with two-stage detectors like Faster R-CNN.
-
Small object detection improves significantly.
-
Hard negatives no longer dominate learning.
7. Advantages and Disadvantages of BCE vs Focal Loss
Binary Cross-Entropy: Pros & Cons
Advantages
-
Simple, stable, widely used
-
No hyperparameters
-
Works for all binary tasks
-
Efficient and less computationally expensive
-
More reliable probability calibration
Disadvantages
-
Struggles with class imbalance
-
Easily dominated by majority class
-
Lower recall for minority class
-
Not ideal for object detection or rare-event prediction
Focal Loss: Pros & Cons
Advantages
-
Excellent for imbalanced datasets
-
Increases recall dramatically
-
Focuses training on hard examples
-
Reduces impact of easy/majority samples
-
Great for object detection and high-stakes tasks
Disadvantages
-
Requires tuning (α, γ)
-
Slightly more computationally expensive
-
May overfit to extremely hard examples if γ too high
-
Probability calibration becomes less accurate
8. Code Comparison: BCE vs Focal Loss
Binary Cross-Entropy (PyTorch)
Focal Loss (PyTorch)
9. When Should You Use Which? (Final Summary)
| Scenario | Best Loss Function |
|---|---|
| Balanced dataset | BCE |
| Imbalanced dataset (moderate imbalance) | Focal Loss |
| Extreme imbalance (1:1000 or worse) | Focal Loss |
| Probability calibration required | BCE |
| Object detection | Focal Loss |
| Rare event prediction | Focal Loss |
| Fast training needed | BCE |
| Avoid hyperparameter tuning | BCE |
Bottom Line
-
Use Binary Cross-Entropy for standard binary classification with balanced or lightly imbalanced datasets.
-
Use Focal Loss when dealing with high class imbalance and when hard examples matter more than easy ones.
In 2025 and beyond, as ML applications increasingly handle rare events, anomalies, fraud, and small objects, Focal Loss is becoming a must-know technique for practitioners.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/mbzuai-researchers-introduce-pan-general-world-model/
NVIDIA AI Introduces TiDAR — “Think in Diffusion, Talk in Autoregression”

