Introduction: The Need for Private AI Has Never Been Greater
With the modern age, which is already defined by the prevalence of artificial intelligence in such areas as medicine, banking, and smart devices as personal assistants, the protection of the user data is, therefore, the paramount concern. This has raised the risk of the weaknesses of concentrated data locations and large off-site training owing to the fast development of these systems.
Federated learning is a critical solution to these issues as it allows developing machine-learning models without passing unencrypted information to a central server; the model goes to the data. The paradigm labeled as privacy-first is quickly becoming the prop of what has become known as Privacy AI.
In the discussion to follow, I look at the ideals, practical architecture, benefits, real-life implementations and future trends of federated learning in the context of the future of artificial intelligence in general.
1. What Is Federated Learning?
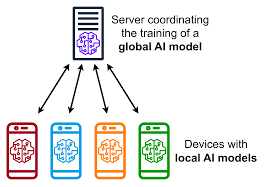
I would like to describe the principle of federated learning (FL), a modern model of a machine learning practice; that trains algorithms across decentralized and collaborating devices or servers with their local data sets without communicating their data directly to those of other devices.
Consider the case of a group of smartphones: in each device, there exists a set of local data items that are owned privately, but there is no data that is uploaded to the cloud. Rather, model-training is made locally on each phone. A global model is refined by only the updates in the resulting model, and not the data, which are aggregated and sent to a central server.
The paradigm was first proposed by Google AI in 2017 and became notably popular in areas where privacy protections are demanded rigidly such as healthcare, finance, and telecommunication.
2. How Federated Learning Works (Step-by-Step)
Let’s break it down into a simplified process:
-
Model Initialization: A central server initializes a machine learning model and sends it to multiple devices.
-
Local Training: Each device trains the model using its local data (like keyboard usage or app behavior).
-
Model Update Sharing: Only the model’s weight updates are sent back to the server—not the user’s data.
-
Aggregation: The central server aggregates all updates using methods like Federated Averaging to produce an improved model.
-
Repeat: This process is repeated for multiple rounds to refine the model.
When discussing ethical aspects of large-scale data use, one must mention the fact that the supposed conflict between the effectiveness of granular models and the quality of privacy of users remains present. Our recent work has shown that we can accomplish all these by training on device and avoid “exposing” the personal data altogether, with little or no loss of predictive faithfulness. These results are especially interesting when considering mobile-focused applications, where not only computational limitations but also the ensuing privacy issues make the implementation of centralized or cloud-centered systems difficult.
3. Why Is Federated Learning Crucial for Privacy AI?
The Centralization models of Artificial Intelligence (AI) requires sensitive data to be posted in cloud servers opening up the triple threat of increased risks of data breaches, difficulties to comply with regulations and reduced trust of users.
Comprehending the reasons of why such problems occur shows their structural basis. Centralized AI systems allocate the computing resources to distant servers instead of putting processing capabilities into the gadget. As a result, the data used to train the models and inference will have to travel through network channels that leads it to the risk of external attacks. In case of a successful breach, privacy and intellectual property are affected, as they can leak confidential information (technically, regardless of whether it is personally identifiable or proprietary).
The exposure is also intensified by law and regulations. As an example, the General Data Protection Regulation (GDPR) set forth by the European Union requires controllers to reach a level of diligent care, which is used to protect personal data. Although providing cloud providers with strong security framework might meet this requirement, threat of failure still exists, and enforcement authorities across the world have routinely penalised companies due to lack of defensive moments in handling the data.
An understanding of these concerns has prompted most organizations to reconsider their AI implementation approaches. The proposed solutions range all the way between federated learning (models are only trained with the encrypted local datasets, never leaving the client devices), to on-device processing where enough higher-level computations are embedded to handle the process on the edge. These two alternatives are able to avoid the main data-security issue which is exposure on the network.
Federated learning, on the other hand, enables:
-
Data Minimization: Raw data never leaves the user’s device.
-
Regulatory Compliance: Easier alignment with GDPR, HIPAA, and CCPA.
-
User Trust: Builds credibility by keeping data private.
-
On-device Intelligence: Enables AI to function even in low or no connectivity zones.
This makes FL a foundational technology for Privacy-Preserving Artificial Intelligence (PPAI).
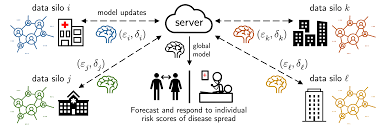
4. Real-World Use Cases of Federated Learning
Here’s where federated learning gets exciting. Many industries are already leveraging it:
Smartphones & Predictive Text
As a part of the Google ecosystem, the Gboard keyboard now also uses federated learning (FL) in order to improve typing suggestions on a device, thus making it unnecessary to forward keystroke data to cloud storage.
Federated learning is a new paradigm of distributed machine learning whereby training data may be used to train models without data centralization. On the contrary, the parameters of the models are popularized to edge nodes and then they are updated in a local manner, and then the updated parameters will be sent back to cloud. This way, Gboard will be able to improve the word-prediction engine without affecting the privacy of its users.
With the use of FL in Gboard, Google avoids a number of adversarial risks that it would have otherwise experienced in case raw keystroke data were sent to the cloud. To begin with, the centralized cloud database is an eloquent target of malicious players. Second, storing and processing of keystrokes on the scale of cloud infrastructure is an important privacy and regulatory issue. Third, easy access to huge amounts of keystroke data can be used to create advanced adversarial attacks to language models.
Considering such points, it is possible to note that FL in Gboard can be viewed as the example of a real-life example of a privacy-preserving technology that can eliminate the technologies used to achieve privacy on the similar scale of the cloud-based language models.
Healthcare
Federated learning (FL) is in use in the current environment of healthcare to educate artificial-intelligence-based models of disease recognition–ranging to malignant disease recognition and diabetic retinopathy–with no needs to publish patient data amongst projects institutions. This way, some of the imperatives of the society are met at the same time: the need in scalable, safe, and general
The benefits that can be traced to this framework can be obvious. One, a model trained on data distributed over different non-homogenous institutions produces a more robust generalizable output, more applicability and a great deal of convergence than a model trained on data that lies in just one institution. Second, due to the architecture of this architecture, data are kept local and this eliminates the need of having to seek the consent of patients in sharing their data with other institutions since there is no transmission of the data to external institutions. The anticipated model will therefore be less susceptible to biases applied due to data imbalances or even idiosyncrasies that may be present at particular sites.
Overall, federated learning is a potentially more efficient choice when compared to the typical supervised-training paradigm as the results are measurably better.
Banking & Fraud Detection
Fellow conferees, I would like to state the problem in brief form: our modern financial establishments would collect data on every transaction made highly precise. However, the data privacy can be used to limit the deployment of advanced fraud detection models to mine such data. With all of these measurements how then will we be able to share and aggregate without giving away the identities of individual customers?
The way out is one of the possible tools, adding federated learning architectures, which proved to be useful in facial and speech recognition and other cases, where privacy of data is crucial. It is a general plan of work as follows:
1. Key platform at a central location synchronizes model parameters in different banks.
2. Every bank continues to have complete ownership of its local data of transactions and models unique to the bank.
3. Banks interact with the central platform by informing it of parameter update only.
4. The parameters are then pooled in the central platform to form a common model that indicates the distribution of transactions at a population level.
5. The resultant model is then spread to the individual institutions.
More importantly, step 3 makes sure that only encrypted differential updates are passed thus obfuscating the local training data of each bank. The outcome of all this is that they are able to build a collective model that although it is trained on the transaction data of multiple institutions never reveals a customer level identity.
Autonomous Vehicles
The self-driving cars may produce a huge amount of data that have never been experienced. With the introduction Federal learning (FL), they can share such records in a secure manner, thus enabling them to train edge-specific learning models, like object detection, without reducing the privacy of the users.
IoT & Smart Homes
On-device AI in smart thermostats and home security systems work thanks to federated learning, keeping local sensitive activity logs.
5. Challenges in Federated Learning
While promising, federated learning isn’t without obstacles:
✅ Heterogeneous Data
Data across devices is non-identical (non-IID), which can reduce model accuracy.
✅ Communication Overhead
Transmitting model updates from thousands of devices can be bandwidth-intensive.
✅ Security Risks
Though data stays local, model updates can be reverse-engineered if not properly encrypted.
✅ Hardware Limitations
Not all devices are equipped to handle on-device training, especially older phones or sensors.
✅ Aggregation Bias
Skewed local data distributions can lead to biased models unless well-managed.
Still, researchers are rapidly advancing solutions like secure aggregation, homomorphic encryption, and differential privacy to address these issues.
6. The Future of Federated Learning and Privacy AI
Federated learning is likely to be the default architecture for AI in data-sensitive sectors.
🔒 Integration with Blockchain
Combining FL with blockchain ensures tamper-proof logging and enhances auditability for federated model updates.
🌐 Edge AI Expansion
With 5G and powerful edge chips, federated learning will empower real-time decision making on the edge—ideal for autonomous drones, smart cameras, etc.
⚙️ Open Federated Learning Frameworks
Projects like TensorFlow Federated, PySyft, and Flower are democratizing FL and speeding up adoption across startups and researchers.
🌍 Global AI Collaborations
FL can foster cross-border AI development without violating local data protection laws—especially useful in global pandemics or climate modeling.
7. Comparison with Other Privacy Approaches
Let’s put FL in context with other privacy-enhancing technologies:
| Technique | Data Location | Use Case | Privacy Level |
|---|---|---|---|
| Centralized ML | Cloud Server | General AI | Low |
| Federated Learning | Local + Server | Personalized & collaborative | High |
| Differential Privacy | Any (added noise) | Anonymizing datasets | Medium to High |
| Homomorphic Encryption | Encrypted cloud data | Secure cloud computation | High but costly |
| Split Learning | Part client, part server | Deep learning hospitals | High |
As you can see, federated learning balances privacy, performance, and practicality better than most.
Real-World Applications of Federated Learning
1. Healthcare
In healthcare, data privacy is not just a regulatory concern but a moral one. Federated learning enables hospitals and research institutions to build robust machine learning models using distributed patient data without violating HIPAA or GDPR regulations. For instance, multiple hospitals can collaboratively develop diagnostic AI for detecting diseases like cancer or COVID-19 using patient scans without sharing raw medical images.
Example: Google and the University of Chicago launched a study using federated learning to improve breast cancer detection. The data remained within hospitals, but the model gained from all contributors.
2. Finance & Banking
Financial institutions cannot afford data breaches. Federated learning lets banks train models on customer data across different branches or banks without centralizing it. Use cases include fraud detection, credit scoring, and personalized financial planning.
Example: Visa is exploring federated learning to detect real-time fraudulent credit card transactions by allowing models to learn from spending patterns across countries.
3. Smartphones and Edge Devices
This is one of the most common and visible applications. Federated learning allows your smartphone to become smarter over time without uploading personal data to cloud servers. Google Keyboard (Gboard) uses federated learning to predict your next word while keeping your typing data local.
4. Autonomous Vehicles
Car companies use federated learning to improve self-driving algorithms using data collected by thousands of vehicles—without sending sensitive location and user behavior data to central servers.
5. Retail and E-commerce
Retailers can optimize inventory, pricing, and customer recommendations without violating customer privacy. Federated learning enables predictive analytics using decentralized sales and behavior data across store branches or customer devices.
Challenges in Federated Learning
Despite its promise, federated learning is not a silver bullet. Several technical and practical challenges remain:
1. Data Heterogeneity
Data collected at each local node may be significantly different due to geographical, behavioral, or temporal variations. This “non-IID” (non-identically independently distributed) data creates a bias that can reduce model performance.
2. Communication Overhead
Federated learning involves frequent transmission of model parameters between devices and a central server (or among peer nodes). This can be costly and slow, especially over poor internet connections or in mobile settings.
3. Security Threats
Even though raw data is not shared, federated learning is not inherently secure. Adversaries can exploit model updates to infer private information—a vulnerability known as gradient leakage or model inversion attacks.
4. Client Dropout and Availability
In real-world environments like mobile phones or IoT devices, clients may frequently go offline, shut down, or be unavailable. This disrupts the training process and may reduce model accuracy.
5. Lack of Standardization
Federated learning frameworks and tools are still evolving. There’s a lack of standardized protocols for interoperability, deployment, and monitoring across diverse infrastructures.
Future Trends in Federated Learning and Privacy AI
The next few years will see federated learning mature from a research topic to an industry standard. Here are the most promising trends:
1. Federated Analytics
Unlike traditional federated learning, which focuses on training predictive models, federated analytics will enable organizations to compute statistical metrics over decentralized datasets. This is useful for aggregated insights without training full ML models.
2. Secure Federated Learning (SFL)
Combining federated learning with secure multi-party computation (SMPC) and homomorphic encryption will ensure that even model updates remain encrypted and secure. Companies like OpenMined and IBM are exploring this heavily.
3. Decentralized Federated Learning
Using blockchain or peer-to-peer networks, future systems may eliminate the central server altogether. This will democratize AI even further and reduce single points of failure.
4. Personalized Federated Learning
Personalization is a hot trend. FL models are being designed to provide each user with tailored insights while still benefiting from collective learning.
Example: Your phone’s predictive keyboard may soon offer suggestions that are not only locally relevant but globally intelligent—thanks to federated personalization.
5. Federated Learning in Edge AI
As edge computing grows in IoT, wearables, and remote sensors, federated learning will become essential. Real-time decisions like anomaly detection, predictive maintenance, and smart city applications will leverage privacy-aware AI at the edge.
Humanized Conclusion: Why It Matters
I would like to pose the main question of trust as the starting point of the discussion. Federated learning is a unique paradigm in the modern times of extensive surveillance, consent fatigue, and Data misuse and aims to foster a combination of wisdom and virtue.
Take two examples. Imagine, first of all, a virtual federation of doctors around the world supporting each other in diagnosing rare diseases without ever exchanging a single patient file. Second, consider a worldwide community of Smartphones constantly improving the abilities of each other, without intruding into the privacy of each of them. It is not a progressive shift in technology; it is a quantifiable shift in social growth.
The future course of artificial intelligence therefore originates beyond the quest of a continuously ascending accuracy index. The opportunity to deploy a responsible intelligence is the critical issue–in fact, in my opinion, the most critical issue in our time–the question of how to create systems that do good things today but never cause any harm. In the realm, federated learning through its explicit intent on Privacy-first principles is taking the charge.
Final SEO-Boosting Summary
Privacy AI and federated learning represent a fundamental change in paradigm of machine learning implementation. Allowing decentralized training of models and ensuring the privacy of personal data, which is impossible to omit when working with industries like healthcare, finance, and the Internet of Things, these technologies are redefining the practice in the industry. Problems persist, in particular the data heterogeneity and resulting communications overhead, but advances in secure computation and federated personalization are steadily closing the gaps. With an increasing number of people anticipating AI to be ethical, federated learning has become an attractive paradigm that balances innovation and honesty.
Conclusion: A Privacy-First AI Revolution Is Here
Fellow workers, I am happy to announce that Federated learning has now transcended its existence to be actualized in real world systems and these systems run in large scale. The knowledge of this decentralized AI paradigm is life-sustaining whether you are an executive or a software developer or a technologically active member of the academic community in the age when data were called the new oil, however, personal privacy is now the new gold.
Whether it is keeping the medical records secure or making the smartphones more useful yet not invade the privacy of the user, the federated learning is turning out to be the future-friendly system that can provide smart experiences without touting the element of trust.
In the nearest few years, I would expect the Privacy AI enabled by the same federated technology to take over various industries, promote regulatory conformity, and, above all, develop trust in the minds of the users.
FAQs about Federated Learning & Privacy AI
Q1: Is federated learning better than centralized machine learning?
Not always. Centralized ML can be more accurate in controlled environments, but federated learning is superior for privacy, data sovereignty, and distributed systems.
Q2: Can federated learning work offline?
Yes, devices can train models offline and send updates when reconnected to the network.
Q3: What companies are using federated learning today?
Google, Apple, Meta, NVIDIA, and startups like Owkin (healthcare AI) and Edge Impulse (IoT) are using or researching FL-based AI systems.
Q4: Is federated learning secure?
It’s more private than traditional ML, but not invulnerable. Techniques like secure aggregation and differential privacy enhance its safety.
Q5: Can I implement federated learning in Python?
Yes! Libraries like TensorFlow Federated, Flower, and PySyft make it easier to get started
Robotics in 2025: The Rise of Intelligent Machines Shaping Our Future
AI-Powered Cybersecurity in Crypto: How Binance and GiveRep Are Leading the Defense in 2025

