
DeepSeek AI Researchers Introduce Engram
Introduction
In late 2025, DeepSeek — a research group known for pioneering work in memory-augmented neural systems — unveiled Engram, a new neural architecture designed to bridge short-term perception and long-term conceptual memory inside large-scale AI agents. Engram is not just another memory module. It represents a principled attempt to encode, retrieve, and evolve compact, interpretable memory traces (“engrams”) that let AI systems form durable, generalizable knowledge across tasks, modalities, and time.
This article explains what Engram is, the motivations behind its design, how it works, and what it might mean for the future of agentic AI. We’ll cover technical underpinnings at a high level, practical applications, current limitations, and ethical considerations.
Why memory matters in modern AI
Modern large language models and multimodal agents excel at pattern recognition, next-token prediction, and short-horizon planning. But they typically struggle with two related problems:
- Long-term consistency: agents often forget earlier interactions or re-learn the same facts across sessions. This makes personalized or cumulative behavior hard.
- Cross-task generalization from sparse experience: when exposed to small amounts of task-specific data, models rarely produce compact, reusable knowledge representations.
Researchers argue that memory is the missing ingredient for more humanlike intelligence. Biological brains store information as distributed yet durable traces that can be reactivated and recombined. Engram takes inspiration from neuroscience (the term “engram” itself refers to hypothesized physical traces of memory in the brain) and engineering (efficient indexing, representational compression) to design a memory system for AI agents.

What is Engram?
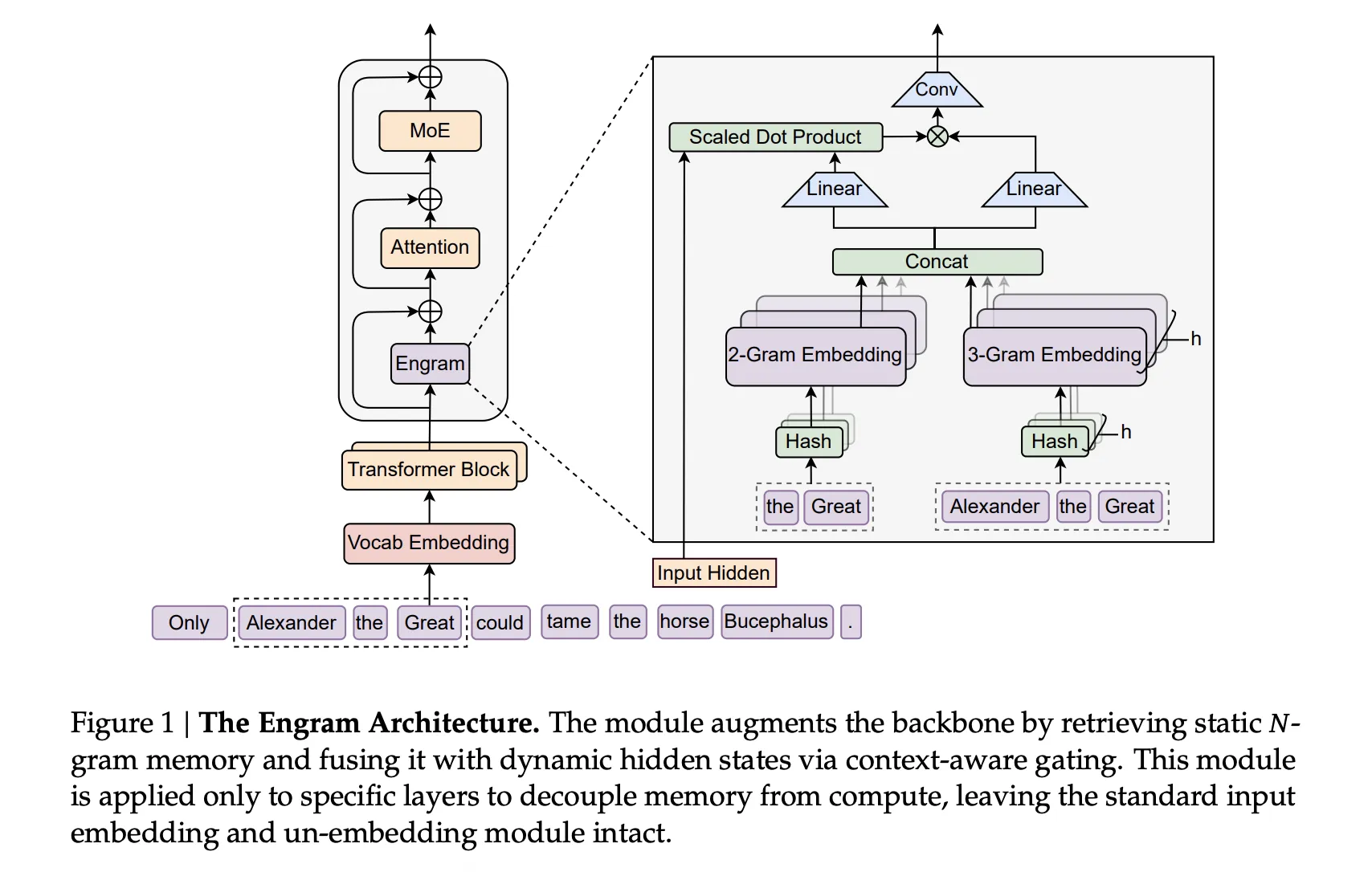
At its core, Engram is a modular memory layer that generates, stores, and retrieves compact memory objects tied to observed events, decisions, or learned concepts. Each Engram memory object contains three main components:
- Context vector: a dense embedding that situates the memory in the agent’s representational space.
- Sparse symbolic sketch: a small, human-interpretable summary (keywords, tags, or short pseudo-symbols) that aids fast retrieval and debugging.
- Associative metadata: time, modality, confidence, and pointers to raw evidence (text, image patches, audio snippets, or code fragments).
The key novelty claimed by DeepSeek is the dual-path encoding strategy: Engram encodes experiences in a continuous latent space while simultaneously constructing a sparse symbolic sketch. This hybrid allows both dense semantic searches (via similarity between context vectors) and precise, fast symbolic lookups (via the sparse sketch). The result is a memory system that supports both fuzzy generalization and crisp recall.
How Engram works (high-level technical view)
Here’s a simplified walk-through of the Engram pipeline:
- Perception & encoding: As the agent perceives input (text, image, audio), a multimodal encoder produces a high-dimensional embedding. A transformer-based compressor reduces this embedding to a fixed-size context vector optimized for downstream retrieval.
- Sketch extraction: A parallel lightweight extractor produces a sparse sketch: a handful of salient tokens or symbolic attributes derived from attention maps and gradient saliency. These are post-processed into canonical tags with a small rule-based normalizer so sketches remain consistent across episodes.
- Storage & consolidation: New Engrams are written into a hierarchical store. Short-term Engrams live in an LRU-style cache; those that are reactivated frequently undergo consolidation (a form of soft merging) into longer-lived slots. Consolidation uses an overlap-aware merging algorithm so that related Engrams compress without catastrophic interference.
- Retrieval & reactivation: When the agent needs to answer, plan, or act, a query embedding is computed and used to perform a two-stage retrieval: (a) symbolic filter using sketches narrows candidate Engrams; (b) dense similarity ranking on context vectors returns the best matches. Selected Engrams are reactivated into working memory as contextual hints.
- Meta-learning & updating: The Engram system learns which traces are useful through a meta-learning signal: Engrams that contribute positively to downstream loss (or to user satisfaction proxies) receive higher consolidation scores and are prioritized for retrieval.
This design mixes neuro-inspired ideas (consolidation, sparse sketches) with pragmatic engineering (hybrid indexing, hierarchical caches), which DeepSeek claims yields scalable, interpretable memory.
Key design principles and innovations
DeepSeek highlights several design principles that distinguish Engram from prior memory systems:
- Hybrid representation: combining dense vectors and sparse sketches for both flexible generalization and efficient symbolic filtering.
- Plasticity-stability balance: a consolidation mechanism that allows memories to both change with new evidence and retain stable content over long periods.
- Modality-agnostic evidence pointers: Engrams can reference raw multimodal evidence, enabling cross-modal reasoning (e.g., linking a visual observation to a textual description).
- Interpretable summaries: sketches are intentionally human-readable to help debugging and to allow alignment checks by operators.
- Learning-to-remember: Engram uses meta-signals to discover which experiences are worth keeping, moving beyond naive frequency or recency heuristics.
How Engram compares to other memory approaches
Many recent papers proposed memory layers for transformers, retrieval-augmented generation (RAG), and episodic controllers. Engram differs in a few practical ways:
- Compared to simple RAG stores (which often index raw documents), Engram focuses on compact, composable memory traces that are both retrievable by similarity and addressable by symbols.
- Compared to end-to-end dense memory matrices, Engram’s hybrid sketch allows faster symbolic constraints and more interpretable outputs.
- Compared to systems that write everything (write-everything logs), Engram learns to curate memories through consolidation and meta-learning, preventing unbounded growth and noisy retrieval.
These distinctions make Engram especially well-suited for lifelong learning agents that interact with users repeatedly and must form stable beliefs across time.
Practical applications
Engram promises improvements across several domains:
1. Personalization and long-term agents
Agents equipped with Engram can remember user preferences, past conversations, and multi-step tasks across sessions — enabling personalized assistants that become more useful over time without explicit re-training.
2. Research assistants and knowledge workers
For domain experts, Engram can accumulate experiment notes, hypotheses, and incremental findings across months. The associative metadata and pointers let users trace a conclusion back to raw evidence.
3. Robotics and embodied agents
Robots can store compact representations of places, object states, and successful maneuvers. Consolidation allows robots to build stable map-like memories from repeated exploration.
4. Education and tutoring platforms
An Engram-enabled tutor can track a learner’s misconceptions, successful strategies, and sensitive progress markers, tailoring interventions based on long-term memory patterns.
5. Multimodal creative workflows
Artists and designers can have agents that recall prior assets, stylistic sketches, and transformations. Because Engram stores pointers to raw media, the agent can present relevant visual evidence alongside textual suggestions.
Limitations and open research questions
Despite its promise, Engram raises several practical and scientific questions:
- Scalability trade-offs: hybrid indexing and consolidation reduce growth, but in large-scale deployments memory still needs careful engineering for latency and storage budgets.
- Forgetting vs. fidelity: deciding what to consolidate or forget remains hard. Meta-signals may favor widely useful traces and lose rare-but-important experiences.
- Bias and privacy risks: storing user-specific Engrams creates risks if memory traces leak or are misused. Memory curation must be paired with privacy-preserving mechanisms (encryption, selective forgetting, on-device storage).
- Evaluation benchmarks: current benchmarks poorly measure lifelong, cross-modal memory. New benchmarks that test temporal consistency, causal recall, and downstream utility are necessary.
- Interpretability at scale: while sketches improve transparency, a huge store of sketches can still overwhelm operators. Tools for summarizing and pruning memory at scale are required.
Safety and ethical considerations
Memory in AI is a double-edged sword. Better memory improves usefulness but also amplifies risk. DeepSeek acknowledges this and outlines engineering guardrails:
- Data minimization: Engram adopts policies to avoid storing sensitive identifiers by default and to require explicit user consent for persistent memory.
- Access controls and audit logs: every retrieval and consolidation event is logged, enabling audits to detect misuse.
- User control: users can list, edit, or delete Engrams associated with their account. DeepSeek recommends human-in-the-loop review for memory sharing across organizational boundaries.
From an ethics perspective, persistent memory prompts questions about consent, informed transparency, and the social dynamics of remembered vs. forgotten interactions. Deployment context matters: a medical assistant, for example, requires stricter retention and access policies than a casual creative tool.
Early experiments and results
DeepSeek reports promising early results across tasks designed to measure temporal consistency and sample-efficient generalization. Key takeaways from their initial benchmarks include:
- Agents with Engram showed lower contradiction rates in multi-turn dialogues spanning days compared to baselines that used episodic caches.
- In few-shot transfer tasks, Engram-enabled agents required fewer demonstrations to learn reusable heuristics because consolidated Engrams captured distilled strategies.
- Human evaluators rated Engram agents as more helpful in follow-up sessions, especially when personalization mattered (e.g., remembering explicit user constraints or preferences).
While these results are encouraging, DeepSeek’s papers and preprints emphasize that careful hyperparameter tuning and storage budgeting were critical to observe gains.
How developers can experiment with Engram
DeepSeek has released a reference implementation and a small-scale SDK for researchers interested in exploring Engram-style memory. Practical steps for experimentation include:
- Run the reference encoder on a small multimodal dataset to generate context vectors and sketches.
- Deploy the hierarchical store locally and experiment with consolidation thresholds to see how memory volume evolves.
- Integrate with downstream tasks (dialogue agents, planners, or retrieval tasks) and measure both performance and latency.
Developers should start with domain-limited experiments (single-user personalization or a closed robotics environment) before attempting open-ended lifelong learning.
The road ahead: research directions inspired by Engram
Engram is a step toward memory-grounded AI, but it also opens several fruitful research avenues:
- Causal memory representations: can Engrams capture causal structure rather than mere associations?
- Active forgetting: intelligent strategies to forget harmful or irrelevant traces proactively.
- Memory-aware planning: tighter integration between memory retrieval and multi-step planning so agents can deliberately query memory as part of deliberation.
- Privacy-preserving memory: combining Engram with secure enclaves or federated mechanisms so personal Engrams never leave user devices.
- Benchmarks for lifelong memory: the community needs standardized tasks to measure memory retention, interference, and downstream utility objectively.
Conclusion
DeepSeek’s Engram represents a thoughtful, hybrid approach to building durable, interpretable memories for AI agents. By marrying dense context vectors with sparse symbolic sketches and adding consolidation-driven curation, Engram targets some of the most persistent limitations of current models: lack of long-term consistency and inefficient cross-task knowledge reuse.
Engram is not a silver bullet. It introduces trade-offs in storage, privacy, and evaluation complexity. But as AI systems transition from stateless tools to persistent, assistant-like partners, memory systems like Engram will be essential. Whether Engram becomes the dominant architecture or one of several viable approaches, its ideas — hybrid representation, consolidation, and interpretability — are likely to shape the next generation of memory-enabled AI.
FAQ (short)
Q: Is Engram open source? A: DeepSeek released a reference implementation and SDK under a permissive research license to encourage experimentation, with stricter licensing for production-ready services.
Q: Will Engram make agents “sentient”? A: No. Engram improves memory and continuity but does not grant consciousness or subjective experience. It enables better information retention and recall.
Q: Can Engram be used on-device? A: Parts of Engram (sketching, local caches) are lightweight and feasible on-device. However, large consolidated stores typically require cloud storage or sharding across devices.
Q: How is privacy handled? A: DeepSeek recommends default minimal retention, encryption at rest, user controls for editing/removal, and audit logging for retrieval events.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/confucius-code-agent-cca-large-scale-codebases/
https://bitsofall.com/seta-rl-terminal-agents-camel-toolkit/
Google AI Releases MedGemma-1.5: A Major Upgrade for Open Medical Imaging + Text AI

