
FlashLabs Researchers Release Chroma 1.0 — an open-source, real-time, end-to-end voice AI that brings low-latency, personalized speech-to-speech to the public
Meta: FlashLabs today published Chroma 1.0, an open-source, real-time, end-to-end spoken-dialogue model that combines low latency and high-fidelity personalized voice cloning — a research and engineering milestone for interactive voice AI.
Lead
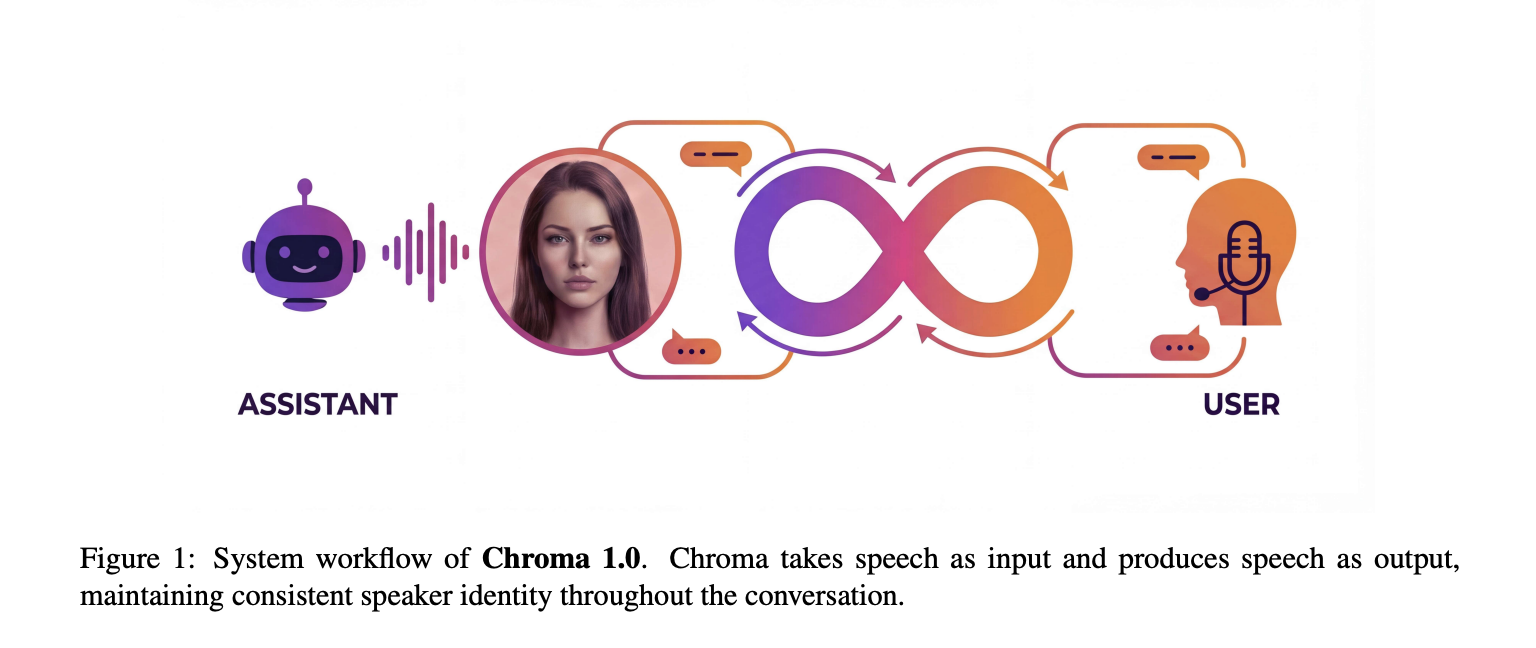
Voice is the last human bottleneck in natural, fluid human–computer interaction: typing and taps are useful, but real conversation is still harder for AI systems to deliver reliably. FlashLabs’ Chroma 1.0 is an attempt to remove that bottleneck by running the entire voice loop end-to-end — from incoming speech to an LLM that reasons on discrete speech tokens to synthesized output — with a design that prioritizes speaker identity preservation and sub-second responsiveness. The project is being released as open-source with paper, code, demos and early benchmarks.
What is Chroma 1.0?
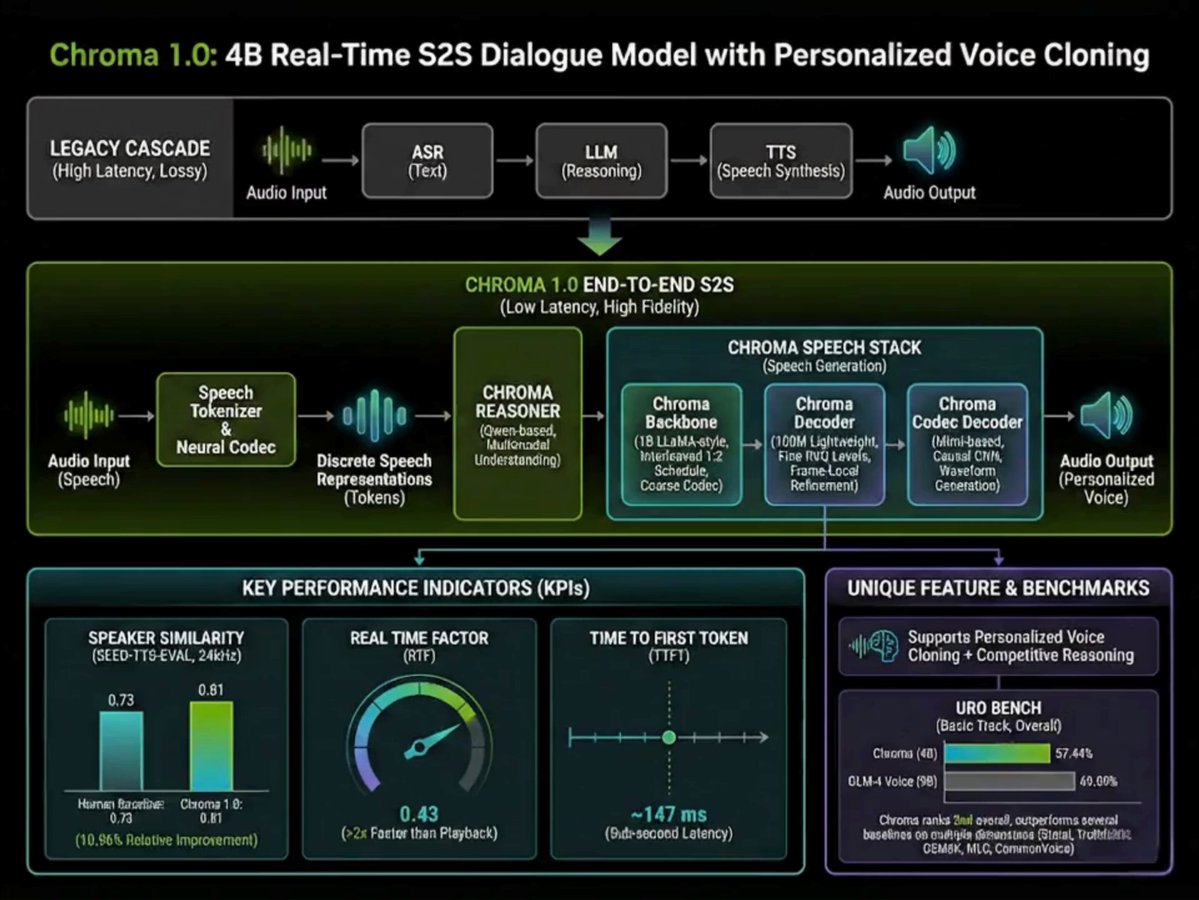
In short: Chroma 1.0 is a research-grade, open-source speech-to-speech dialogue model that operates in real time and supports personalized voice cloning. Unlike classic pipelines that run automatic speech recognition (ASR) → text LLM → text-to-speech (TTS), Chroma uses discrete audio tokenization and an interleaved text-audio token schedule so the LLM can reason directly on audio-aware representations and generate audio tokens back — dramatically reducing latency and improving the ability to preserve speaker identity. FlashLabs presents Chroma as both a model and a full system: training recipes, evaluation, and runtime design aimed at delivering conversationally smooth voice interactions.
(Important naming note: Chroma is also the name used by the popular vector database project—those are distinct projects. Here we’re discussing FlashLabs’ speech model Chroma 1.0.)
Why the architecture matters (short technical primer)
Traditional voice agents split the problem into separate modules: ASR to get text, an LLM to process text and produce text, and TTS to turn the text back to audio. This works, but each transition adds latency and causes fidelity loss of prosody, speaker characteristics, and subtle timing. Chroma’s approach combines these steps by:
-
Tokenizing speech into discrete audio units (neural codec or speech tokenizer) so that both inputs and outputs can be represented as token streams similar to text tokens.
-
Interleaving audio and text tokens in the model’s context (FlashLabs reports a 1:2 text–audio token schedule as part of their latency strategy), letting the model begin generating audio tokens before a full text response has been finalized.
-
Personalized speaker embeddings or conditioning so the generated voice matches the input speaker identity (voice cloning) while maintaining naturalness and intelligibility.
-
Engineering for low time-to-first-token (TTFT) and a favorable real-time factor (RTF), enabling near-conversational turntaking.
This design reduces round-trip latency because the system does not need to wait for a full text pass before producing audible output; it can start emitting audio tokens as soon as it’s confident about the next segment of speech.
Benchmarks & reported performance
FlashLabs publishes objective metrics in their arXiv paper and accompanying release materials. Key highlights they report:
-
Speaker similarity (SIM): Chroma achieves a SIM score of 0.81, reportedly outperforming a human baseline in their experimental setup by about 10.96%.
-
Time-to-first-token (TTFT): ~147 ms end-to-end, meaning the system can begin producing the first output token in under a fifth of a second in their measurements.
-
Real-time factor (RTF): ~0.43, indicating the model runs considerably faster than real time on the hardware used in their evaluation.
Those numbers point to a model that is both fast and good at preserving speaker identity in conversions — at least on the datasets and the hardware described in FlashLabs’ paper. As with all research claims, results depend on evaluation protocols, datasets, and hardware; the release includes the paper and reproducibility details so independent researchers can validate and stress-test those claims.
How Chroma compares to closed alternatives
Closed commercial platforms (for example, OpenAI’s Realtime stack, certain proprietary voice-assistant pipelines, or cloud vendor real-time offerings) often aim for low latency but rely on internal stacks and proprietary models. Chroma’s differentiators:
-
Open-source: researchers and developers can inspect, modify, and run the model — important for transparency, reproducibility, and community–driven improvements.
-
End-to-end design: by operating on audio tokens and interleaving tokens, Chroma reduces latency and preserves voice identity better than many pipelined systems.
-
Research focus on personalization: Chroma emphasizes speaker similarity and cloning that retains speaker identity, which is crucial for use cases such as voice assistants that are expected to maintain a consistent persona or for dubbing/voice-over workflows.
Community demos and early comparisons (including single-turn and multi-turn YouTube tests) show that Chroma can produce fluid multi-turn interactions and voice matches competitive with some commercial solutions — though independent third-party audits and broader benchmarks will better reveal real-world parity.
Real-world uses and opportunities
Chroma 1.0 enables several application areas that benefit from low latency and strong speaker identity:
-
Conversational agents and assistants: more natural voice conversations in homes, cars, call centers or on devices. Lower latency makes turntaking feel human.
-
Personalized voice interfaces: services that talk back in a user’s own voice (with consent), or voice agents that preserve identity across sessions.
-
Localization and dubbing: faster, more natural dubbing where the voice characteristics of the original speaker are preserved; potentially valuable for film, podcasts, and accessibility.
-
Realtime translation/relay: building voice translators that don’t force multiple pipeline hops, which can improve latency and the naturalness of translated speech.
-
Assistive tech: reading aids or conversational prosthetics that require immediate, natural voice feedback.
Because Chroma is open, startups, researchers, and hobbyists can iterate on use cases quickly; however, real deployment requires careful engineering around safety, consent, and compute cost.
Safety, ethics and misuse risks
Any technology that clones or synthesizes voices raises obvious ethical issues — spoofing, impersonation, non-consensual voice cloning, and fraud. FlashLabs acknowledge this general concern and, as an open project, the community should treat safety as a first-class concern. Important mitigation strategies include:
-
Consent & provenance: enforce explicit consent for creating voice clones and maintain provenance metadata so generated audio can be traced.
-
Watermarking: embed inaudible or traceable signals to mark synthesized audio. Research into robust, hard-to-remove audio watermarks is ongoing.
-
Access controls: limit model access and provide tiered interfaces (e.g., lower-fidelity public models, vetted higher-fidelity for verified partners).
-
Policy & regulation: governments and platforms can set rules for identity misuse; technical enforcement will only be part of the solution.
Open-source releases increase the gulf between research and commercial control; they accelerate innovation but also broaden the set of actors who could misuse the tech. Responsible release patterns, clear documentation, and community governance are essential.
Reproducibility and where to try it
FlashLabs published the technical paper and has activity posts on platforms like Hugging Face and LinkedIn announcing the release; demos are available (including performance comparisons on YouTube). The arXiv paper and code pointers should let researchers reproduce training recipes and runtime setups; engineers can also run smaller, locally hosted inference setups to test latency and voice cloning on consumer hardware.
If you’re evaluating Chroma today, here’s a practical checklist:
-
Read the paper to understand training corpora, evaluation protocols, and hardware used for benchmarks.
-
Run the demo to compare output quality and latency on your target hardware (watch multi-turn tests to judge turntaking).
-
Assess dataset & bias — verify whether the training data matches your deployment domain (languages, accents, age ranges, etc.).
-
Plan for safety — add consent, watermarking, and access controls before any public deployment.
Limitations and open questions
Chroma’s reported numbers are impressive, but several caveats matter:
-
Evaluation scope: reported SIM, TTFT and RTF numbers are dependent on the test set, hardware, and protocols FlashLabs used. Independent replication matters.
-
Compute & cost: real-time models require capable hardware; running them at scale may be expensive compared to text-only LLMs or offline TTS. FlashLabs’ RTF numbers suggest efficiency, but production costs depend on concurrency and deployment choices.
-
Accent, language and noise robustness: how well the model performs across languages, accents, and noisy channels needs larger benchmarks.
-
Developer tooling & APIs: the maturity of SDKs, inference pipelines and scaling options will determine how quickly companies can adopt Chroma. The research release is a first step; production wrappers may follow.
Broader impact: why this matters
If the research holds up in independent evaluations, Chroma 1.0 signals an important shift: conversational systems that are both open and genuinely real-time become possible, making high-quality voice agents accessible to researchers and builders outside a few large companies. That accessibility has a double edge: it fuels innovation in assistive tech, accessibility, creative applications, and more, while also pushing the community to build stronger norms and technical defenses against misuse. The net social outcome will depend on how proactively the community and industry act on safety and governance.
Quick developer snapshot (how to get started)
-
Read: Start with FlashLabs’ arXiv paper for architecture and evaluation details.
-
Watch: View the demo comparisons to form a practical sense of latency and voice similarity.
-
Experiment: If code is published on a repo or Hugging Face space, run a small local demo, test TTFT on your device and measure RTF under different batch sizes.
-
Design: Add consent dialogs and provenance metadata for any voice cloning tests you perform.
Conclusion
Chroma 1.0 from FlashLabs is a noteworthy step toward democratizing real-time voice AI. By packaging an end-to-end speech-to-speech model that emphasizes low latency and speaker preserving voice cloning, and by releasing it as open source with papers and demos, FlashLabs hands researchers and builders a powerful tool — and with it a responsibility to design, deploy, and regulate voice technology thoughtfully.
For anyone building conversational experiences, Chroma is worth examining now: it shows a concrete path to making voice interactions feel immediate and personal. For regulators, platform owners, and technologists, it’s also an urgent reminder that voice cloning and real-time synthesis are now widely reproducible — governance and technical safeguards must keep pace.
Sources and further reading
-
FlashLabs — press release announcing Chroma 1.0.
-
Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning (arXiv / PDF).
-
FlashLabs project activity / Hugging Face page.
-
Demo and comparison videos (YouTube).
-
Community discussions and summaries (AlphaXiv / social posts).
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/salesforce-ai-fofpred-forecasting/
https://bitsofall.com/vercel-releases-agent-skills-ai-coding/
Nous Research Releases NousCoder-14B: an open, fast-trained champion for competitive programming

