
Meta and Harvard Researchers Introduce the Confucius Code Agent (CCA): A Software Engineering Agent That Can Operate at Large-Scale Codebases
Software engineering is where “AI that can code” stops being a party trick and starts getting judged like a teammate. It’s not enough to generate a neat function or pass a toy unit test. Real repositories are sprawling, messy, and full of tribal knowledge: build scripts, hidden invariants, long-running test suites, brittle CI pipelines, legacy modules, and the dreaded “works on my machine” configuration drift.
That’s the exact terrain Meta and Harvard researchers target with Confucius Code Agent (CCA)—an open-sourced software engineering agent designed to operate at industrial scale across large codebases, long sessions, and complex toolchains. Instead of betting everything on a bigger base model, CCA argues that agent scaffolding—how you structure memory, tools, orchestration, and iteration—can be the difference between “decent coder” and “reliable repo mechanic.”
In this article, we’ll break down what CCA is, why large-scale repositories are uniquely hard for coding agents, how the Confucius SDK is designed, what makes CCA’s workflow different, and what the benchmark results suggest about the future of AI software engineering.
Why Large-Scale Codebases Break Typical Coding Agents
Most open-source coding agents look impressive on short tasks: implement a function, write a class, patch a single file. But production-grade issue resolution is a different beast. CCA’s paper frames “real-world” SWE as requiring three things simultaneously:
-
Reasoning over massive repositories (many files, many layers, many dependencies)
-
Long-horizon sessions (multi-step debugging, refactoring, iterating)
-
Robust toolchain coordination at test time (search, edit, run tests, inspect logs, repeat)
Without those, agents often fall into common failure modes:
-
They lose key decisions made earlier (“context collapse”).
-
They thrash—re-discovering the same repo facts repeatedly.
-
They misuse tools (bad edits, wrong commands, unsafe shell actions).
-
They can’t keep a coherent plan across multi-file changes.
This is why proprietary systems sometimes perform well: they’ve quietly built strong scaffolding around their models. But those systems can be hard to inspect, extend, or reproduce. CCA’s goal is to provide an open and extensible “industrial-grade” scaffolding stack that can be studied and adapted.

What Is Confucius Code Agent (CCA)?
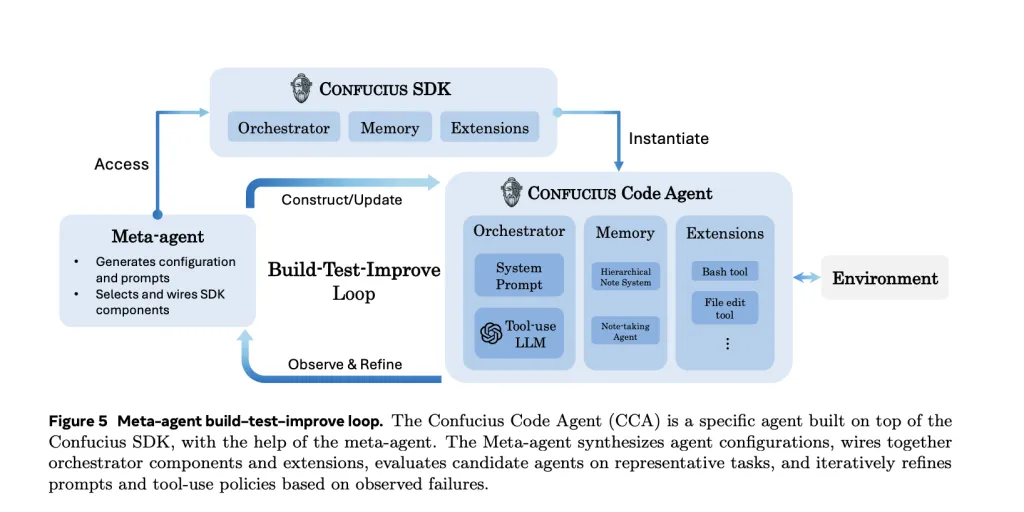
Confucius Code Agent (CCA) is presented as an open-sourced AI software engineer built to handle industrial-scale repositories, with durable memory and tool robustness. Importantly, it’s not just “a prompt” or “a model wrapper.” It’s an agent instantiated on top of an agent development platform called the Confucius SDK.
The core claim is simple but powerful:
Under identical repo environments, tool access, and model backends, better scaffolding can yield major gains in real SWE outcomes—sometimes outperforming stronger models paired with weaker scaffolds.
The Confucius SDK: Building Agents Like Products, Not Demos
CCA is built on the Confucius SDK, which is structured around three “experience” layers:
-
AX (Agent Experience): how the agent reasons, remembers, and acts reliably
-
UX (User Experience): how a human interacts with the agent and its outputs
-
DX (Developer Experience): how builders extend, debug, and iterate the agent stack
Instead of treating these as afterthoughts, the SDK explicitly designs for them. This matters because a coding agent isn’t just generating text—it’s driving a toolchain, manipulating files, and producing patches that must survive CI.
The paper highlights four key mechanisms (often referred to as features) that collectively make CCA “industrial scale”:
-
F1: Context Management (Hierarchical Working Memory + Adaptive Compression)
-
F2: Note-taking (Persistent Cross-Session Memory)
-
F3: Extensions (Modular Tooling Contracts)
-
F4: Meta-agent (Build–Test–Improve Loop for Agent Configs)
Let’s unpack each.
F1: Hierarchical Working Memory for Long-Context Reasoning
Large repo work is inherently long-context:
-
You investigate an issue.
-
You form hypotheses.
-
You locate relevant files and call chains.
-
You make edits.
-
Tests fail.
-
You inspect logs.
-
You revise.
-
You refactor.
-
You re-test.
Many agents either dump everything into the prompt until they hit context limits, or they truncate in a way that silently deletes critical decisions. Confucius SDK tackles this via a context management layer using hierarchical working memory plus adaptive context compression—so the agent can keep essentials while compressing raw history.
The point isn’t just to avoid token overflow. It’s to preserve coherence: the “why” behind decisions, the constraints discovered, the current plan, and the debugging state.
F2: Persistent Note-Taking That Survives Across Sessions
A surprising weakness of many coding agents is that they’re “brilliant goldfish.” Even if they solve something once, they can’t reliably reuse the insight later unless it’s reintroduced into context.
CCA introduces a note-taking module where a dedicated note-taking agent distills trajectories into persistent Markdown notes in a structured tree (e.g., project/architecture.md, recurring issues, fixes, failure patterns). These notes become an externalized, human-readable memory that can be retrieved later.
This is especially relevant for:
-
recurring CI failures,
-
environment setup quirks,
-
“gotchas” in specific subsystems,
-
and repeated refactoring patterns.
In other words, CCA tries to accumulate practical engineering knowledge the same way a real team does: not only in commits, but in docs and runbooks.
F3: Extensions: Tool Use as a Modular System, Not Hardcoded Glue
Tool use is where agents either become useful or dangerous.
CCA’s SDK includes a modular extension system—each extension has a well-defined contract, callbacks are logged, and tool behavior can be upgraded independently of the agent’s core loop. In CCA, the “agent” is essentially an orchestrator plus a selected bundle of extensions: file editing, CLI, code search, planning, caching, and others.
That design has two big benefits:
-
Reliability: tool policies can be hardened without rewriting the agent.
-
Reusability: improvements (like safer shell patterns or better file-edit parsing) can be shared across agents built on the SDK.
F4: The Meta-Agent: Automating Agent Engineering Itself
One of the most interesting components is the meta-agent, which can automatically refine agent configurations through a build–test–improve loop. Instead of humans manually tuning prompt rules and tool policies forever, the meta-agent:
-
synthesizes candidate configurations,
-
wires components and extensions,
-
evaluates on representative tasks,
-
observes failures,
-
and iteratively improves prompts/tool conventions.
This reframes “agent design” as an optimization process, not a one-time prompt-writing exercise. It’s also a pragmatic answer to a real pain: different repos and orgs require different policies. A monorepo with strict CI gates is not the same environment as a small Python library.
Benchmark Results: SWE-Bench-Pro and the Case for Scaffolding
CCA evaluates on SWE-Bench-Pro and reports Resolve Rate (Pass@1)—the percentage of tasks where the proposed patch passes all repository tests without human intervention.
Main SWE-Bench-Pro results (public split)
From the paper’s Table 1:
-
With Claude 4 Sonnet:
-
SWE-Agent baseline: 42.7
-
CCA: 45.5
-
-
With Claude 4.5 Sonnet:
-
SWE-Agent: 43.6
-
Live-SWE-Agent: 45.8
-
CCA: 52.7
-
-
With Claude 4.5 Opus:
-
Anthropic system card (reported): 52.0
-
CCA: 54.3
-
The headline is not just the 54.3 number—it’s the comparison logic the authors emphasize: identical environments, and gains attributed to the scaffold rather than “just use a stronger model.”
Ablations: What Actually Drives the Gains?
CCA also reports ablations that isolate two major contributors:
-
hierarchical context management
-
tool-use sophistication (including meta-agent learned conventions)
In a 100-example subset of SWE-Bench-Pro:
-
Claude 4 Sonnet improves from 42.0 → 48.6 with advanced context management enabled.
-
For Claude 4.5 Sonnet, removing sophisticated tool-use patterns and reverting to a simpler pattern reduces performance significantly (Table 2), indicating that learned tool-use conventions are a major driver of CCA’s performance.
This supports a broader point: once models are “good enough,” engineering quality often comes from systems design—memory, orchestration, safe tooling, and iteration loops.
Long-Term Memory Evaluation and “Don’t Relearn What You Already Learned”
Because benchmarks rarely test cross-session memory, the authors also explore memory behavior by running tasks in consecutive passes, saving notes for a subset of instances, and re-running with those notes available to measure efficiency and quality changes.
The practical implication is obvious: in real engineering, repeated issues happen constantly. If an agent can accumulate a growing “knowledge base” of repo-specific fixes and patterns, it starts to behave less like a chatbot and more like an internal developer tool that improves over time.
A Qualitative Comparison: PyTorch-Bench and Real Debugging Workflows
The paper also describes a custom mini PyTorch-Bench, built by scanning GitHub issues in the PyTorch repo, intended to highlight realistic debugging and development tasks on a larger codebase. The authors mention limitations in directly comparing certain systems due to tool interface and execution environment differences, so these experiments are positioned as complementary and qualitative.
Even without treating it like a strict leaderboard score, this matters because it pushes evaluation closer to “how agents feel” in daily developer life: reading logs, navigating huge trees, making multi-file edits, and iterating under constraints.
Why CCA Matters for the Future of AI Software Engineering
CCA is part of a trend: the industry is realizing that “AI coding” is less about a single brilliant completion and more about workflow reliability.
Here are the biggest takeaways:
1) Agent scaffolding can be more important than model size
CCA’s results suggest a well-designed scaffold can let a weaker model compete with stronger ones under weaker scaffolds.
2) Memory is not optional in real repos
The combination of hierarchical working memory (in-session) and persistent notes (across sessions) reflects how real engineers work: you keep a working plan, and you keep durable artifacts.
3) Tooling needs contracts, logs, and safety policies
If an agent edits files and runs commands, you want it to be inspectable, modular, and debuggable—especially for enterprise adoption.
4) The meta-agent idea scales agent development
Instead of “one agent to rule them all,” organizations will want specialized agents: CI triage, refactoring assistants, dependency upgrades, security patching, release-note generation. A build–test–improve loop helps adapt agents to each environment faster.
Practical Ways This Could Be Used in Teams
If you run or contribute to large codebases, CCA-style systems point to workflows like:
-
Issue-to-PR automation: agent reads issue, locates code, patches, runs tests, submits PR.
-
CI failure triage: agent identifies failing tests, inspects recent changes, proposes fix.
-
Refactoring at scale: agent plans multi-file changes while maintaining repository invariants.
-
Onboarding accelerator: agent generates “repo map” notes, architecture summaries, and runbooks.
Even if you never run CCA directly, the design patterns—hierarchical memory, persistent notes, extension contracts, and meta-agent tuning—are increasingly the blueprint for serious SWE agents.
Limitations and What to Watch Next
CCA is promising, but it’s also a reminder that SWE agents remain probabilistic systems:
-
Benchmarks like SWE-Bench-Pro are strong proxies, but they still don’t capture every enterprise constraint (security policies, internal services, proprietary tooling).
-
Tool execution environments matter; direct comparisons can be tricky when systems differ in containerization and tool interfaces.
-
Long-term memory introduces governance questions: what gets stored, how it’s validated, and how teams prevent “bad notes” from accumulating.
The next wave of research will likely focus on:
-
tighter evaluation for cross-session learning,
-
safer tool policies,
-
and organization-specific agent specialization.
Conclusion
Confucius Code Agent (CCA) is a strong signal that AI software engineering is maturing from “model demos” to systems engineering. Meta and Harvard’s work argues that once models reach a certain capability, the biggest wins come from how you orchestrate: structured memory, durable note-taking, modular tools, and iterative meta-agent optimization.
If you’re building for real-world repositories—monorepos, legacy systems, or anything with a serious CI pipeline—CCA’s design is less a single product and more a playbook: treat an SWE agent like a production system, not a prompt.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/stanford-sleepfm-ai-disease-prediction/
https://bitsofall.com/google-gemini-integration/
Implementing Softmax From Scratch: A Complete Guide for Machine Learning Practitioners
OpenAI “Atlas” AI Browser: The Next Evolution of Web Browsing (and Why It Matters)

