
NVIDIA’s Nemotron 3 “Agentic” Model Series: What It Is and Why It Matters
For the last few years, NVIDIA has been known primarily as the company powering the AI boom from underneath: GPUs, networking, and the software stack that makes training and serving large models possible. But in December 2025, NVIDIA made a very direct statement in the open-model world: it debuted Nemotron 3, a family of open models, data, and libraries designed specifically for agentic AI—systems that don’t just answer, but plan, use tools, collaborate with other agents, and complete multi-step work reliably. NVIDIA Newsroom+2NVIDIA Developer+2
Nemotron 3 is positioned less like “one more chatbot model” and more like a production-ready toolkit for building autonomous applications—customer support automation, IT ticket triage, research copilots, workflow agents, robotics support systems, and internal enterprise assistants that can actually follow a process end-to-end.
In this guide, we’ll break down what Nemotron 3 is, how the Nano / Super / Ultra sizing strategy maps to real deployments, what “agentic” means in practice, and how you can architect autonomous systems around the series.
1) What NVIDIA Released: Nemotron 3 as a Model Family (Not a Single LLM)
NVIDIA describes Nemotron 3 as a family of open models aimed at powering transparent, efficient, and specialized agentic AI development across industries. NVIDIA Newsroom+1
The lineup is organized into three tiers:
-
Nemotron 3 Nano — the smallest tier, optimized for efficiency and high-throughput inference
-
Nemotron 3 Super — optimized for collaborative agents and high-volume workloads
-
Nemotron 3 Ultra — the largest tier, aiming for top-end accuracy and reasoning for the most complex tasks NVIDIA+2NVIDIA+2
As of the initial announcement (Dec 15, 2025), Nano is available now, while Super and Ultra are planned for release in the coming months / first half of 2026. NVIDIA+1
This “family” strategy matters for autonomy because most real-world agentic systems benefit from multiple specialized models, not one giant brain. In production, you often want:
-
a fast “worker” model for routine steps,
-
a stronger “planner/reasoner” model for tricky decisions,
-
and sometimes a heavyweight “judge/critic” model to validate outputs.
Nemotron 3 is explicitly shaped for that kind of multi-model orchestration. arXiv+1

2) What “Agentic Models” Really Means (Beyond the Buzzword)
When people say “agentic,” they usually mean a model can do more than respond—it can:
-
Plan: break a goal into steps
-
Act: use tools/APIs (search, databases, ticket systems, code execution, RPA)
-
Observe: read tool outputs and update its state
-
Iterate: continue until completion
-
Coordinate: work with other agents (specialists)
-
Control reasoning cost: trade speed vs depth depending on the task arXiv+1
In Nemotron 3’s case, NVIDIA highlights post-training geared toward multi-step tool use and multi-environment reinforcement learning, plus granular reasoning budget control—all of which are features you’d want in autonomous pipelines where cost, latency, and reliability have to be managed tightly. arXiv+1
3) The Architecture: Hybrid Mamba–Transformer + Mixture-of-Experts (MoE)
A major technical differentiator in Nemotron 3 is its architecture direction: NVIDIA describes a Mixture-of-Experts hybrid Mamba–Transformer approach, designed to deliver best-in-class throughput and very long context (up to 1M tokens in the family). NVIDIA+2arXiv+2
Why this matters for agentic systems:
A) Throughput drives autonomy
Agentic applications don’t just generate one answer. They generate:
-
a plan,
-
multiple tool calls,
-
intermediate summaries,
-
follow-up prompts,
-
and final outputs.
So the “cost per completed task” isn’t just about model size—it’s about how efficiently you can run many turns of reasoning. NVIDIA emphasizes Nemotron 3 as an efficiency-focused open family for high-throughput agentic workloads. NVIDIA+1
B) MoE helps keep inference affordable
Mixture-of-Experts typically activates only part of the network per token, aiming to preserve capability while reducing compute per step. In Nemotron 3 Nano’s technical positioning, NVIDIA explicitly frames it as achieving strong agentic/reasoning ability while activating a smaller subset of parameters per forward pass, improving throughput. NVIDIA+1
C) Long context changes how agents “remember”
A key promise here is up to 1M-token context support, with practical defaults sometimes set lower due to VRAM requirements. That’s important: long context enables a single agent to hold large project histories, knowledge bases, ticket threads, or codebase context—reducing the need for constant retrieval, chunking, or lossy summarization. NVIDIA+1
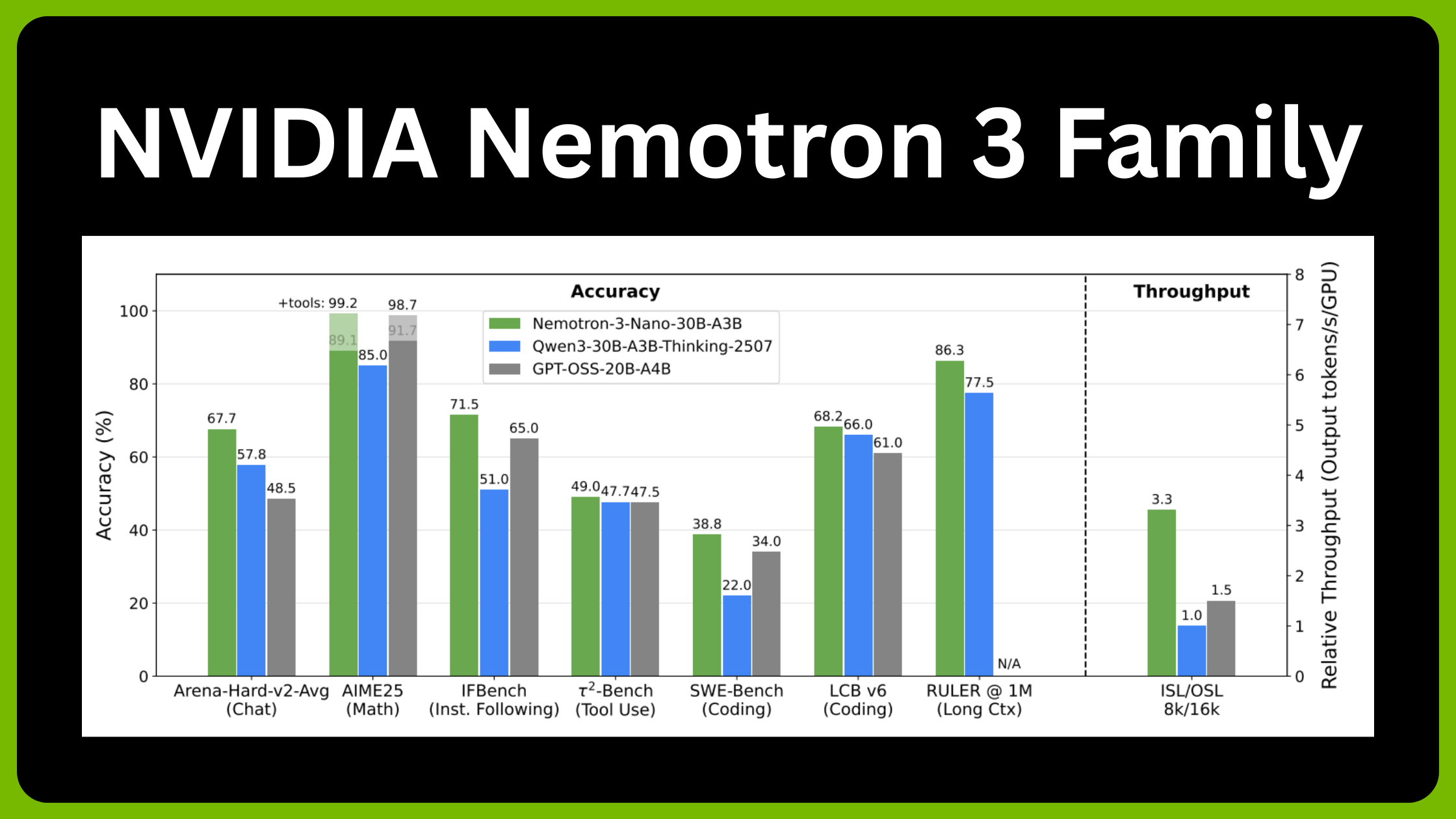
4) Model Sizes and Roles: Nano vs Super vs Ultra
NVIDIA’s naming (Nano/Super/Ultra) isn’t just marketing—each tier maps neatly to a different job inside an autonomous system.
Nemotron 3 Nano: The high-throughput “worker”
Nano is positioned as the smallest, most cost-efficient model for inference, while still showing strong agentic, reasoning, and chat ability. It also supports long context (up to 1M tokens, with configuration defaults often lower). NVIDIA+2Hugging Face+2
Think of Nano as ideal for:
-
tool-call execution steps (API formatting, SQL drafting, parsing outputs),
-
routine customer support flows,
-
classification/routing,
-
document Q&A with large context windows,
-
code refactors where speed matters more than “deepest possible reasoning.”
NVIDIA and third-party coverage also describe Nano’s efficiency as a key feature for multi-step tasks in production. Reuters+1
A concrete example is the openly released NVIDIA-Nemotron-3-Nano-30B-A3B variants on Hugging Face. Hugging Face+1
Nemotron 3 Super: The collaborative “team lead”
Super is described as optimized for collaborative agents and high-volume workloads such as IT ticket automation. NVIDIA+1
That implies a sweet spot where:
-
the model is strong enough to coordinate tasks,
-
can maintain a clearer plan across long workflows,
-
but is still efficient enough to run at scale for enterprise queues.
In an agentic architecture, Super is a strong candidate for:
-
planner role (task decomposition),
-
coordinator role (assigning subtasks to specialized tools/agents),
-
policy role (ensuring outputs comply with business rules).
Nemotron 3 Ultra: The heavyweight “strategist / verifier”
Ultra is positioned as the most capable tier, aimed at state-of-the-art accuracy and reasoning performance. NVIDIA+1
In autonomy, Ultra is useful when:
-
decisions are expensive to get wrong,
-
reasoning depth matters (multi-hop logic, complex constraints),
-
you need a “final boss” verifier to reduce hallucinations and enforce correctness.
A practical strategy is to use Ultra sparingly:
-
only escalate the hardest 5–10% of tasks,
-
or run it as a “critic” that audits plans/results produced by Nano/Super.
This is one of the most effective ways to keep agentic systems both reliable and cost-controlled.
5) Nemotron 3 Nano in the Real World: What’s Actually Available Today
At launch, NVIDIA made it clear that Nano is available now, with models distributed through channels like NVIDIA’s ecosystem and Hugging Face. NVIDIA Developer+1
On the Hugging Face model card, NVIDIA notes:
-
compatibility with Transformers,
-
recommended NeMo Framework version,
-
and that while the model can support up to 1M context, default configuration may be lower (for practical VRAM reasons). Hugging Face+1
This “practical default vs max capability” detail is important for anyone building autonomous applications: long context is powerful, but you’ll want to design your system so it can gracefully operate at smaller windows too (using retrieval, summaries, or state compression).

6) Openness and Licensing: Why Enterprises Care
NVIDIA emphasizes Nemotron as a family of open models with open components intended for customization and secure evaluation. NVIDIA Developer+1
On NVIDIA’s Nemotron foundation model page, the company describes an Open Model License positioned as permissive for using, modifying, distributing, and commercially deploying models and derivatives. NVIDIA
This matters in regulated enterprise and government contexts, where teams often ask:
-
Can we run it fully on-prem?
-
Can we fine-tune it on internal data?
-
Can we audit behavior and measure risk?
-
Are we locked into a hosted API contract?
Nemotron 3 is designed to be a “downloadable, modifiable, testable” model family, aligning with the broader market push toward models that can be treated like infrastructure rather than a black-box service. WIRED+1
7) How Nemotron 3 Enables Autonomous Applications
Let’s translate the technical claims into real deployment patterns.
Pattern A: Long-context autonomy for “casework”
Think: insurance claims, compliance checks, HR onboarding, legal doc review, procurement approvals.
These problems are usually:
-
document-heavy,
-
multi-step,
-
and require referencing many earlier details.
A long-context model like Nemotron 3 Nano (with support up to 1M tokens) can reduce the complexity of stitching together dozens of chunks and summaries, especially when the workflow needs to stay consistent over time. NVIDIA+1
Pattern B: Tool-using agents for enterprise workflows
Agentic systems become real when they can call tools:
-
ticket creation and updates,
-
CRM lookups,
-
knowledge base retrieval,
-
inventory systems,
-
CI/CD pipelines,
-
analytics dashboards.
Nemotron 3’s post-training focus on multi-step tool use suggests it’s being tuned specifically for that “plan → call tool → interpret → continue” loop. arXiv+1
Pattern C: Multi-agent systems (specialists) at scale
Nemotron 3 is explicitly marketed around building multi-agent systems at scale, which usually looks like:
-
Planner agent (sets steps, allocates tasks)
-
Research agent (retrieves relevant info)
-
Writer agent (produces polished outputs)
-
Validator agent (checks policies, correctness, completeness)
NVIDIA’s family approach (Nano/Super/Ultra) fits this: you can choose different tiers for different roles, instead of forcing one model to do everything. NVIDIA Newsroom+2NVIDIA+2
8) Choosing the Right Size: A Practical Decision Guide
If you’re building autonomous applications, the “best” model is the one that completes tasks reliably at the lowest total cost (compute + engineering + failures). Here’s a simple way to choose among Nemotron 3 tiers:
Choose Nano when:
-
You need high throughput (many concurrent tasks)
-
Most steps are routine, structured, and tool-driven
-
You can add guardrails and validations
-
Latency matters (interactive agents, support queues) NVIDIA+1
Choose Super when:
-
You need stronger planning and coordination
-
Tasks have branching logic and require better judgment
-
You’re orchestrating multiple sub-agents at scale NVIDIA+1
Choose Ultra when:
-
The cost of being wrong is high (finance, safety, compliance-heavy actions)
-
Tasks require deep reasoning across constraints
-
You want a “verifier/critic” model to audit outputs from cheaper agents NVIDIA+1
A strong production pattern is: Nano for 80–90% of steps, Super for planning, Ultra for escalation and verification.

9) A Reference Architecture: Building an Agentic System with Nemotron 3
Here’s a clean blueprint you can adapt:
Step 1: Define roles
-
Router (Nano): classify intent, pick workflow
-
Planner (Super): break task into steps, choose tools
-
Executor (Nano): run tool calls, parse outputs, update state
-
Critic/Auditor (Ultra): validate final result, ensure compliance
Step 2: Build a shared state
Use a structured memory object (JSON) to store:
-
user goal
-
constraints
-
completed steps
-
tool results
-
open questions
-
citations / source references (if required)
Long context helps, but explicit state makes systems more reliable.
Step 3: Put guardrails around actions
Before any irreversible action (send email, close a ticket, approve an order), add:
-
policy checks,
-
human-in-the-loop gates,
-
and/or Ultra-based auditing.
Step 4: Measure “task success,” not just token accuracy
Agentic systems should be evaluated on:
-
completion rate,
-
tool-call correctness,
-
time-to-resolution,
-
user satisfaction,
-
and cost per completed workflow.
NVIDIA’s broader Nemotron tooling emphasis (open recipes, evaluator approaches) aligns with this operational mindset. NVIDIA Developer+1
10) What to Watch Next: Super and Ultra Releases
NVIDIA’s research page for Nemotron 3 states clearly that Nano is released now and Super/Ultra will follow. NVIDIA
So if you’re planning a system today, you can:
-
start building with Nano immediately,
-
design your orchestration so it can later “swap in” Super for planning,
-
and add Ultra as a verification layer when it becomes available.
This staged approach is also smart engineering: get your workflow, tools, and evaluation right with a smaller model first, then scale up capability only where it measurably improves outcomes.
Conclusion: Nemotron 3 Is “Agentic Infrastructure,” Not Just Another LLM
Nemotron 3 is NVIDIA’s attempt to package open models into a practical autonomy stack: long context, high throughput, agentic post-training, and a family of sizes that can be mixed and matched across multi-agent systems. NVIDIA Newsroom+2arXiv+2
If you’re building autonomous applications—especially enterprise workflows where cost, governance, and on-prem deployment matter—Nemotron 3’s direction is worth serious attention. Nano is already available for teams who want to start now, while Super and Ultra are positioned to complete the “planner + verifier” layers that advanced agentic systems rely on. NVIDIA Developer+2NVIDIA+2
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/gemini-3-flash-rapid-ai-apps/
https://bitsofall.com/next-generation-research/
Deepfake Detection: Technologies, Challenges, and the Future of Trust in the Digital Age

