
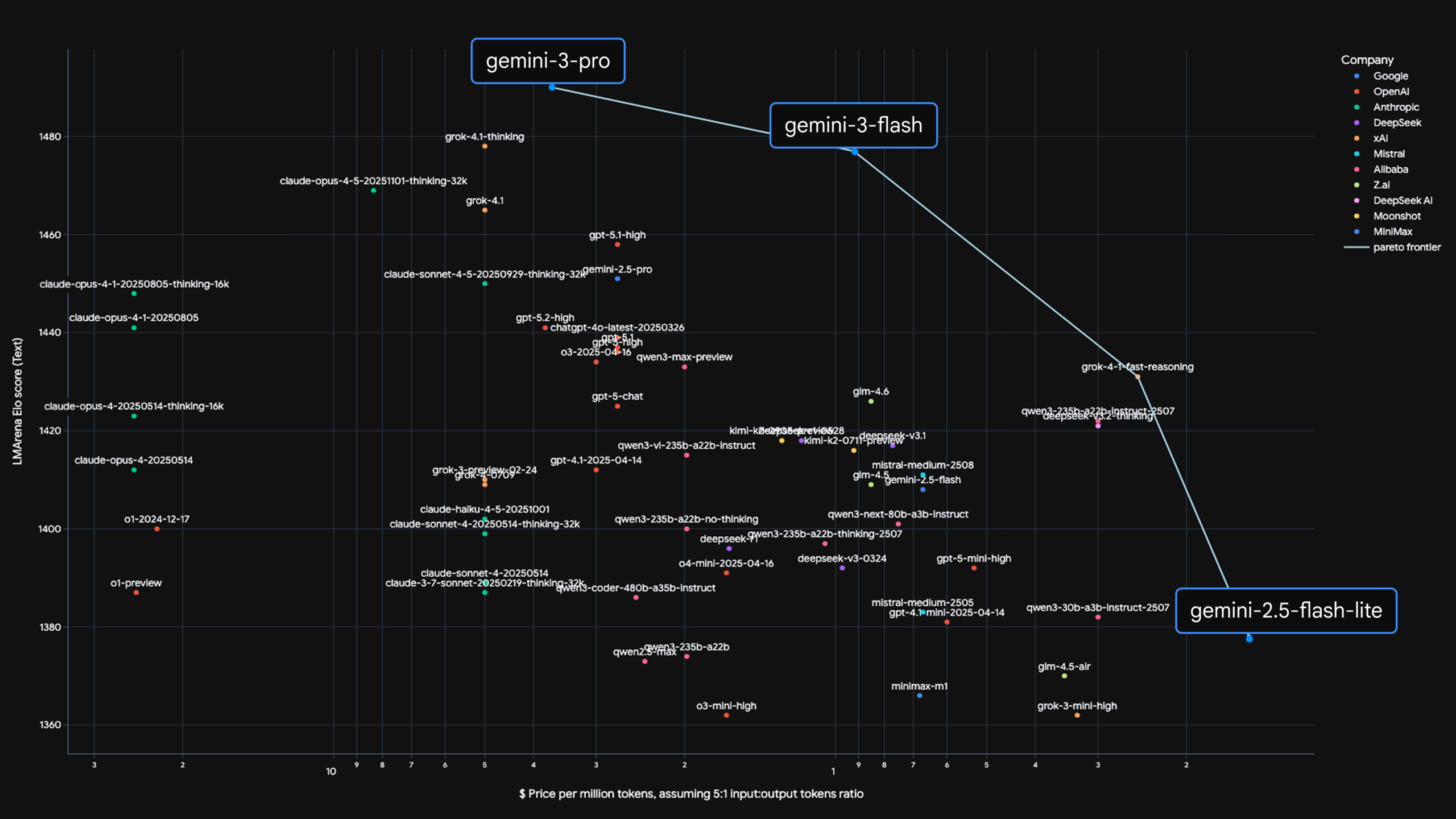
Google’s Lightweight Gemini 3 Flash Model for Rapid Applications
Building “fast” AI products used to mean accepting trade-offs: you could ship a low-latency model that responded quickly but struggled with complex reasoning, or you could use a heavier “Pro” model that gave better answers but introduced noticeable delays and higher cost. Google’s Gemini 3 Flash is designed to close that gap—delivering Pro-grade intelligence at Flash-level speed so teams can build responsive, production-ready experiences without constantly juggling model tiers. blog.google+1
In this guide, we’ll break down what makes Gemini 3 Flash “lightweight,” where it fits in the Gemini 3 family, how it performs in rapid applications, and how to integrate it into real systems—from customer-facing chat to agentic workflows and coding copilots.

What is Gemini 3 Flash—and why “lightweight” matters?
Gemini 3 Flash is a model in Google’s Gemini 3 series positioned for speed, efficiency, and scale. Google describes it as offering Pro-level intelligence with the speed and pricing characteristics of Flash, making it ideal for interactive and high-throughput workloads. Google AI for Developers+1
When people say “lightweight” in production AI, they typically mean:
-
Lower latency (fast responses that feel instant)
-
Lower inference cost (cheaper per request or per token)
-
Higher throughput (more requests per second per deployment)
-
More predictable performance under load
Gemini 3 Flash is explicitly engineered for those conditions—so you can run real-time features (assistants, autocomplete, extraction, agents) without the app feeling sluggish or the bill exploding.
Google has also rolled it out broadly—making it the default model in the Gemini app and in AI experiences like Search AI Mode, which signals confidence in its ability to handle massive real-world traffic. blog.google+2Workspace Updates Blog+2
Core capabilities that enable rapid applications
1) Pro-grade reasoning at low latency
Flash models traditionally prioritize speed. What’s notable about Gemini 3 Flash is the claim that you’re not sacrificing reasoning to get that speed. Google positions it as “frontier intelligence built for speed,” aiming to support complex tasks—like coding and analysis—in interactive settings. blog.google+1
Why it matters:
If your user experience depends on multi-step reasoning—triaging a support issue, interpreting a table, fixing a code error, or planning an action—latency spikes can ruin the product. A fast model that still reasons well can unlock features you previously reserved for expensive “Pro” calls.
2) Native multimodality (text + more)
Gemini models are built to work across modalities. Gemini 3 Flash is positioned as a practical multimodal engine for apps that need to understand mixed inputs (for example: a screenshot + instructions, or a document + questions). Google AI for Developers+1
Rapid-app examples:
-
“Explain this error message” from a screenshot
-
“Extract invoice fields” from a scanned PDF image
-
“Summarize this slide deck” with visual elements
-
“Answer questions about this chart” quickly
3) Robust function calling for real-world actions
Modern apps increasingly rely on tool use / function calling: the model doesn’t just answer—it triggers actions like “search the database,” “create a ticket,” “send an email,” or “book an appointment.”
Gemini 3 is explicitly marketed around building agents and multimodal apps with strong tool support. Google AI Studio+1
Why it matters for speed:
Function calling reduces back-and-forth prompting. Instead of the model guessing, it can request exactly the data it needs, and your app returns it—often cutting total time-to-resolution.
4) Grounding and production controls (cost + reliability)
Google’s ecosystem includes features like grounding with Google Search (for up-to-date info) and context caching (to reuse expensive prompt context across requests). The Gemini API pricing page lists these capabilities and their cost structure, which is crucial when you’re designing rapid applications with repeated context (like a long policy doc, a codebase, or a knowledge base). Google AI for Developers
Practical takeaway:
For rapid apps, speed isn’t only model latency—it’s also how often you have to resend huge context. Caching can reduce both time and cost when users iterate quickly.
Where Gemini 3 Flash fits in the Gemini stack
Google’s Gemini 3 lineup includes models aimed at different trade-offs. The Gemini API documentation describes:
-
Gemini 3 Pro for the most complex tasks requiring broad knowledge and advanced reasoning
-
Gemini 3 Flash for Pro-like intelligence at Flash speed/pricing
-
Additional specialized offerings (including image-generation models) Google AI for Developers
A very practical pattern emerges:
-
Use Flash for most user interactions (chat, extraction, quick analysis, routing, tool calls).
-
Escalate to Pro only when you detect very complex reasoning needs or high-stakes outputs.
Google even highlights “auto-routing” concepts in developer tooling like Gemini CLI, where you can reserve Pro for the hardest prompts while letting Flash handle the bulk of work. Google Developers Blog
Best-fit use cases for rapid applications
1) Real-time assistants and chat experiences
If you’re building a front-end assistant inside a product—e-commerce support, HR self-service, finance Q&A, or student help—speed is the product. Gemini 3 Flash is positioned as ideal for everyday tasks like summarization, document analysis, and data extraction where responsiveness matters. Workspace Updates Blog
What to build:
-
Instant answers with “show your source” style grounding
-
“Ask this document” workflows
-
Multi-turn customer support that can call tools (CRM, tickets, policies)
2) High-volume document extraction and classification
Lightweight models shine when the same operation repeats thousands of times:
-
Extract fields from invoices, resumes, KYC docs
-
Classify messages into categories
-
Detect intent and route tickets
-
Summarize calls/chats
Gemini 3 Flash is marketed as efficient for data extraction and rapid analysis, which maps directly to these pipelines. Workspace Updates Blog+1
3) Coding copilots and developer workflows
Google and DeepMind materials emphasize coding performance and speed, including examples that highlight faster generation of complex outputs (like functional visualizations) with better token efficiency. Google DeepMind+1
Rapid-app ideas:
-
IDE assistant that proposes fixes instantly
-
CLI helper that refactors code and writes tests
-
Code review bot that flags issues and suggests patches
-
“Explain this repo” on-demand for onboarding
4) Agentic workflows that must feel instant
Agents are only useful if they can:
-
understand a goal,
-
call tools,
-
reason over results,
-
take the next step—fast.
Google’s enterprise messaging positions Gemini 3 Flash for agentic coding and responsive applications, available across enterprise surfaces (Vertex AI, Gemini Enterprise, Gemini CLI). Google Cloud+1
Examples:
-
“Plan and book my itinerary” (search + calendar + email tools)
-
“Reconcile these transactions” (load data + analyze + create report)
-
“Monitor incidents” (log search + summarize + open ticket)
5) Search-enhanced and up-to-date experiences
Making Gemini 3 Flash a default in Search-related experiences suggests it’s built for rapid, interactive query answering. Grounding with Search can reduce hallucinations for current facts—useful when your app needs live information. blog.google+1
How to integrate Gemini 3 Flash (practical architecture)
Here’s a production-friendly blueprint for “rapid apps”:
Step 1: Use a fast system prompt + tight output schema
-
Keep system prompts short and operational
-
Force structured outputs (JSON) for extraction
-
Include strict refusal/safety rules for your domain
Step 2: Prefer tool calls over “guessing”
If the model needs account status, order history, inventory, or policy text—don’t paste everything. Let it call tools:
-
getCustomer(order_id) -
searchPolicy(query) -
createTicket(...)
This improves correctness and reduces prompt bloat.
Step 3: Cache repeat context
If the user is chatting about the same document or codebase, cache it. The Gemini API pricing docs explicitly list context caching options and rates, which can be a big win in iterative workflows. Google AI for Developers
Step 4: Add escalation logic
Use Flash first. Escalate to Pro only when:
-
the user asks for a high-stakes decision
-
the task requires deep multi-hop reasoning
-
the model confidence is low
-
the tool results are ambiguous
This gives you “Pro quality” where it counts without paying Pro costs on every message.
Cost and scaling considerations (what teams usually miss)
Even with a fast model, costs can climb if you design the app poorly. Common pitfalls:
-
Sending giant context on every turn (fix: caching + retrieval)
-
Overly verbose outputs (fix: strict output limits + summaries)
-
No batching for offline tasks (fix: batch endpoints where applicable)
-
No rate limiting (fix: per-user quotas, backoff, queueing)
Google publishes pricing tables for Gemini API usage, including input/output token costs and features like caching and grounding. Use those numbers early in design so your unit economics don’t surprise you later. Google AI for Developers

Gemini 3 Flash in Google’s product ecosystem
Gemini 3 Flash isn’t only an API model—it’s being pushed across user-facing and enterprise surfaces:
-
Google’s official product messaging frames it as “built for speed” and now widely accessible. blog.google
-
Workspace updates describe Gemini 3 Flash as ideal for everyday tasks like summarization, document analysis, and extraction. Workspace Updates Blog
-
Enterprise announcements emphasize availability in Vertex AI, Gemini Enterprise, and Gemini CLI for business-scale deployments. Google Cloud+1
This matters because it reduces friction: your team can prototype in AI Studio, deploy in Vertex, and support developer workflows in CLI—while using the same underlying model family.
When not to use Gemini 3 Flash
Even great “fast” models have limits. Consider escalating when:
-
The task requires maximum precision (legal/medical) and you need extra verification layers
-
The user wants long-form, deeply technical reasoning with extensive proofs
-
You’re doing complex planning with many constraints and high risk
-
You need the absolute best multimodal reasoning for edge cases
In those cases, a “Pro” model (plus deterministic checks and human review) can be safer.
Final thoughts: why Gemini 3 Flash is a big deal for builders
Gemini 3 Flash represents a clear product direction: ship intelligence at scale by making speed the default, not a compromise. With Pro-like reasoning at Flash-like latency, it’s tailored for the experiences users actually stick with—interactive, responsive, tool-enabled AI inside real products. blog.google+2Google AI for Developers+2
If you’re building rapid applications in 2025—customer support copilots, document automation, coding assistants, or agentic workflows—Gemini 3 Flash is designed to be the “workhorse” model that keeps things fast, affordable, and production-ready.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/xiaomi-open-source-mimo-v2-flash-inference-first-moe-model/
https://bitsofall.com/c3-generative-ai-enterprise-genai-platform/
Next-Generation Research: How Science, AI, and Technology Are Redefining the Future of Discovery

