
Kimi K2 Thinking by Moonshot AI — A New Era of Thinking Agents
In the fast-moving world of large language models (LLMs), every few months there’s a new release promising bigger context windows, more parameters, better reasoning, or tighter cost efficiencies. But few carry the claim — and the evidence — of something genuinely new. With the launch of Kimi K2 Thinking, Moonshot AI has accomplished just that. This article dives deep into what Kimi K2 Thinking is, how it was built, how it performs, what it means for developers and enterprises, and what the risks and next steps are.
(Note: This is a comprehensive, human-friendly, SEO-oriented piece designed to give you a full picture of this landmark release.)
1. Setting the Stage: Why Kimi K2 Thinking Matters
1.1 The broader LLM landscape
For many years now, the formula for progress in LLMs has been: more compute, more parameters, more data, more context. Models like GPT‑4, Claude Opus, and others have pushed the envelope on reasoning, generation, coding, and multimodal input. At the same time, the industry is increasingly focusing on agentic capabilities: the ability for a model not just to respond, but to plan, execute, call tools, chain reasoning steps, and maintain coherence over long dialogues or tasks.
1.2 Enter Moonshot AI
Moonshot AI (based in Beijing, founded in 2023) has moved rapidly to carve out its place in the global AI race. It’s been called one of China’s “AI Tigers”. Wikipedia+1 The company has released a number of its Kimi models (e.g., Kimi-K1.5, Kimi-VL) and now aims for a large scale “thinking agent” paradigm.
1.3 The leap to Kimi K2 Thinking
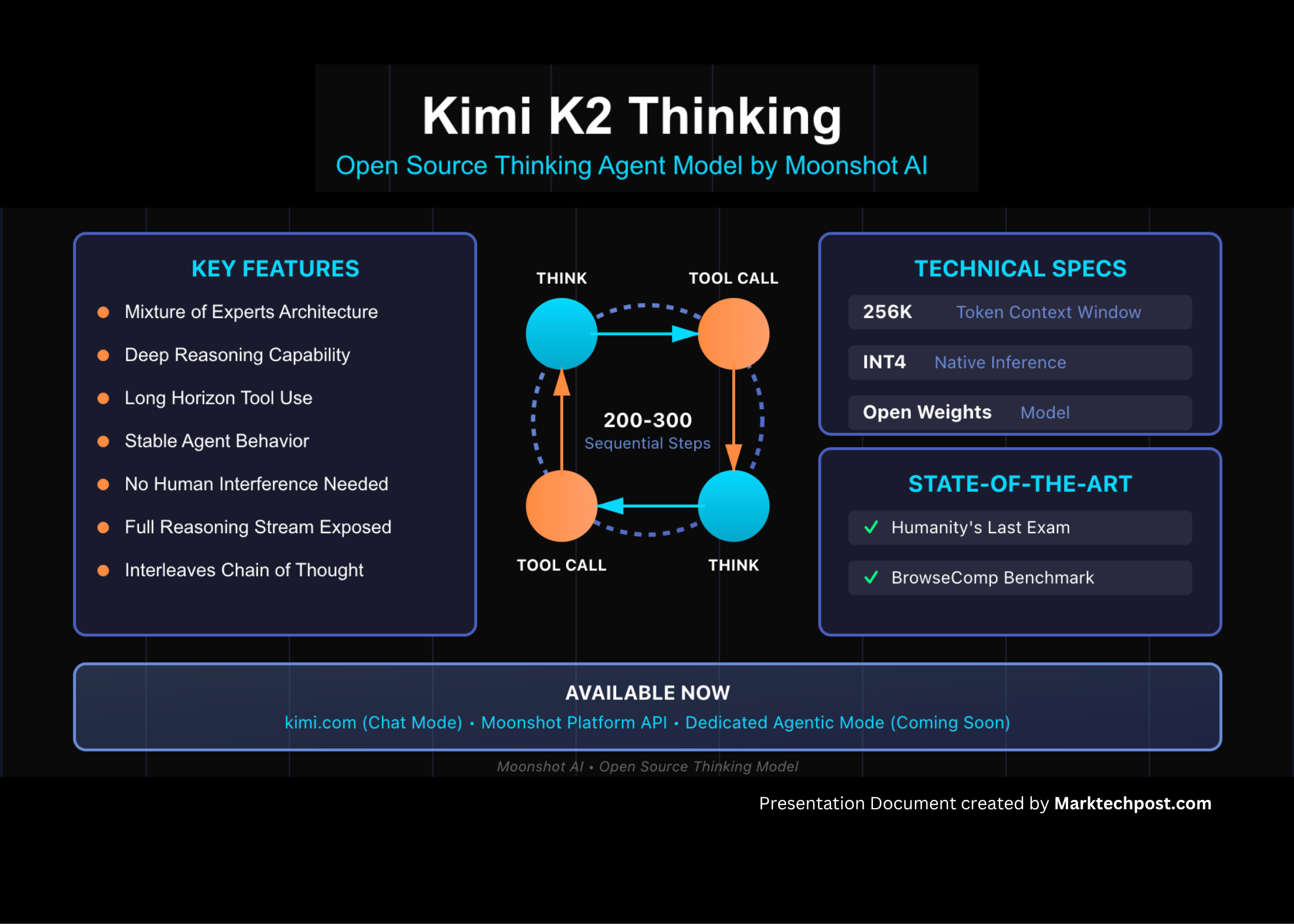
The release of Kimi K2 Thinking heralds a new chapter: a mixture-of-experts (MoE) architecture with a trillion total parameters (1T) and 32 billion active parameters per inference, optimized for deep reasoning, tool-use, and long sequential chains. GitHub+2Hugging Face+2
In other words: it’s not just “a bigger chat model” — it is explicitly framed as a “thinking” model. That distinction is important. The official description says:
“Kimi K2 Thinking … built as a thinking agent that reasons step-by-step while dynamically invoking tools. … 256 k context window, native INT4 quantization …” Hugging Face+2OpenRouter+2
So what does that mean in practice? Let’s examine the architecture, performance, and innovations.
2. Architecture & Technical Highlights
2.1 Mixture-of-Experts (MoE) design
At its core, Kimi K2 Thinking uses a MoE architecture: there are a large pool of “experts” (different sub-networks each specialized) and during inference only a subset of those experts are active. For Kimi K2: total parameters ~1 trillion, but only ~32 billion active per inference. GitHub+2Hugging Face+2
The benefits:
-
Higher capacity without linear cost increase.
-
Specialized routing allows task-specific sub-experts.
-
Efficiency gains in inference: you don’t activate the full network each time.
2.2 Massive Context Window & Quantization
Kimi K2 Thinking offers a context window up to 256,000 tokens (256 k) in its published version. Hugging Face It is also quantized to INT4 (reduced precision) to reduce memory footprint and inference latency while aiming to keep performance intact.
2.3 Tool-use and Agentic Capabilities
Unlike many LLMs that focus on “next-token prediction” in a static sense, Kimi K2 Thinking is engineered for:
-
Sequential tool calls: it can orchestrate perhaps 200-300 chained tool invocations while maintaining coherence. Venturebeat+1
-
Step-by-step reasoning: planning, decomposition of tasks, calling tools, verifying, then outputting.
-
“Thinking agent”-style behaviour: not just answer → respond, but analyze → plan → act → evaluate.
2.4 Training Regimen & Optimizer Innovations
To train such a large MoE model with stability, Moonshot researchers introduced the “MuonClip” optimizer — a derivative of their Muon optimizer — combining novel QK-clip techniques to stabilize training at scale. arXiv+1 They pre-trained on ~15.5 trillion tokens. arXiv+1
2.5 Licensing & Openness
Significantly, Moonshot has released open weights (at least for base/instruct variants) under a Modified MIT license. Medium+1 This means developers and researchers can access and fine-tune or deploy the model — a fact that in the AI world is drawing a lot of attention.
3. Performance & Benchmarking
3.1 Head-to-Head Metrics
As reported:
-
Kimi K2 (non-“Thinking” version) already claims top scores on benchmarks such as SWE-Bench Verified, LiveCodeBench v6, etc. arXiv+1
-
For the “Thinking” variant, Moonshot states:
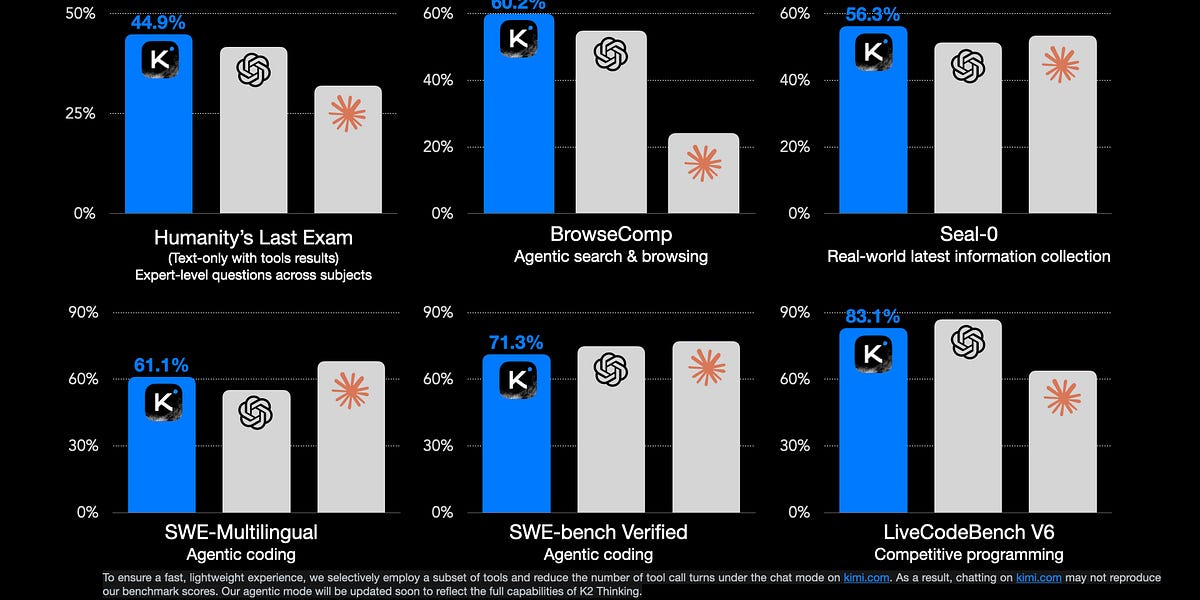
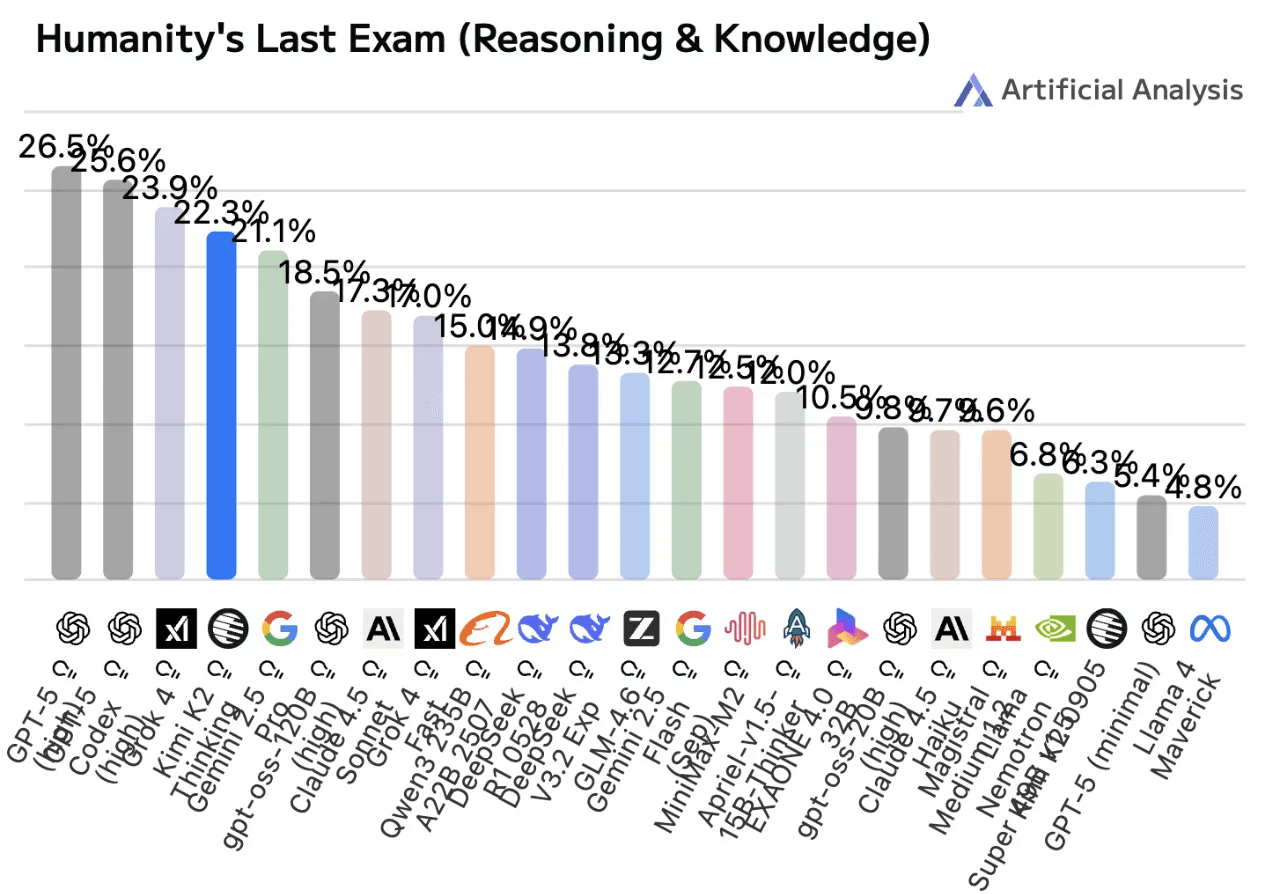
“achieves 44.9 % on Humanity’s Last Exam (HLE) … 60.2 % on BrowseComp … 71.3 % on SWE-Bench Verified … 83.1 % on LiveCodeBench v6…” Venturebeat+1
These results suggest it outperforms previous state-of-the-art open models and even competes with (or surpasses) certain proprietary models.
3.2 Coding, Reasoning & Tool Use Strengths
Observers have noted strong performance in:
-
Multi-step reasoning tasks (rather than “one-turn chat”).
-
Coding and debugging: fixing bugs, generating code, handling multi-language scenarios. Gary Svenson
-
Agentic tasks: chaining operations, calling external tools, managing dependencies.
3.3 Efficiency & Cost Advantages
By virtue of MoE architecture and quantization (INT4), Kimi K2 Thinking offers better inference efficiency (less GPU memory, lower latency) than some monolithic large models. Also, the open-source nature reduces vendor lock-in and cost barriers for deployment.
3.4 Contextual & Long-Form Reasoning
Thanks to the 256 k token window, the model can handle very long documents, deep analyses, or multi-step workflows. This supports use-cases like legal document review, large code bases, or long conversations.
4. Real-World Applications & Use-Cases
4.1 Developers & Coding Teams
For software engineering, Kimi K2 Thinking shines: it can help with code generation, debugging, code review, multi-language support, integration of tool calls (compilers, test runners, static analyzers). The fact that it’s open and deployable means teams can fine-tune for their code-base, internal APIs, or team workflows.
4.2 Enterprise Agents & Automation
Organisations building intelligent agents (for example: “read this 200 k-token document, call external APIs, plan steps, generate report”) can leverage Kimi K2 Thinking explicitly for that. The tool-invocation architecture fits well with process automation, business-workflow orchestration, semi-autonomous agents.
4.3 Research & Innovation
Because weights are accessible, academia and research labs can experiment with custom alignments, new architectures, domain-specific fine-tuning. The openness also supports reproducibility and transparency.
4.4 Long-Form Content, Legal & Medical
With its extended context window, Kimi K2 Thinking can handle large legal contracts, huge medical records, historical archives. Use-cases such as summarisation, extraction, question-answering across many pages of text, and multi-stage reasoning become more feasible.

5. Strategic & Industry Implications
5.1 Open vs. Closed Model Race
The release of Kimi K2 Thinking strengthens the open-model ecosystem. Many previous cutting-edge models were closed, vendor-locked, costly. By opting for open licensing and high performance, Moonshot shifts the balance. This could accelerate friction for closed systems and increase developer choice.
5.2 China’s AI Ambitions & Global Dynamics
Moonshot is a Beijing-based company operating within China’s AI ecosystem. The launch of a model that competes broadly (not just domestically) sends a message about global competitiveness. Reuters+1
5.3 Democratization of “Thinking Agents”
If deep reasoning + tool invocation becomes accessible, more organisations (including smaller ones) can build agents rather than just chatbots. This can change the shape of enterprise AI services, shifting from “ask a chatbot” to “deploy a reasoning workflow”.
5.4 Cost & Infrastructure Considerations
While the headline model is huge (1 T parameters), the MoE architecture means active compute per request is less reactive. Quantization and efficiency gains help, but deploying such models still requires serious infrastructure. This pushes hardware vendors and cloud services to evolve accordingly.
6. What Makes Kimi K2 Thinking Tick: Deep Dive
6.1 Why the MoE architecture matters
Traditional dense models scale linearly: more parameters → more compute. MoE decouples total size from active size. By activating only relevant experts per token, you get capacity without linear cost. Kimi K2 uses 384 experts in one version, selecting about 8 experts per token. GitHub
6.2 Chain-of-thought + tool-invocation training
One of the major advances: the model wasn’t just trained to answer, but to plan and call tools. That means a training pipeline that exposes it to sequences: problem → plan steps → call tool A → tool B → evaluate → output. This training regimen helps the model behave more agentically.
6.3 Long-context support & memory
With a 256 k token window, you can feed in very large inputs: full books, entire code-bases, multi-hour transcripts. It opens up new applications: reasoning across very long documents, context-rich workflows.
6.4 Quantization & inference efficiency
INT4 quantization means the model uses 4-bit precision for much of its weights/inference path, significantly reducing memory footprint and bandwidth. This is critical to make such large models usable in practice.
6.5 Open source mindset
Publishing weights, providing robust APIs, allowing customization: this opens a new wave of AI innovation — the kinds of “developer freedom” we’ve seen in open-source software now more visible in large-model AI.
7. Getting Started & Practical Tips
If you’re a developer or organization thinking of using Kimi K2 Thinking, here’s how to approach it:
-
Check infrastructure readiness – While the active parameter count is “only” ~32 billion, you still need substantial GPU/TPU resources (or cloud equivalently) and memory. Quantized models help, but ensure you can support the context length and tool-invocation pipeline.
-
Pick the right variant – Moonshot offers base, instruct, and “thinking” versions. If you need maximal reasoning + tool-use, go for the “Thinking” version. If your use-case is simpler (chat, summarisation) maybe the instruct variant suffices.
-
Plan for tool orchestration – Using the model’s strength in tool-invocation means you’ll need to design how your agents call APIs, how you monitor flow, handle failures, loop back.
-
Fine-tune/align if needed – Because it’s open-weight, you can fine-tune on domain-specific data (e.g., your code base, legal corpus, enterprise workflow) to improve relevance and reduce hallucination risk.
-
Monitor for safety, bias, hallucination – As with any powerful LLM, strong reasoning capability doesn’t eliminate hallucinations or biases. Proper guardrails, evaluation frameworks, and human-in-the-loop checks remain important.
-
Leverage the long context – If your data involves long documents (books, legal contracts, code projects), utilise the 256 k context window. It’s one of the compelling differentiators.
-
Stay updated on community – Because this model is open-source, you’ll likely see rapid development, community fine-tunes, optimisations, deployment tools. Keep track of repositories, forums, and researcher insights.
8. Limitations & Considerations
Even with its impressive capabilities, Kimi K2 Thinking is not a silver bullet. Some caveats:
-
Hardware & cost: While MoE and quantization reduce cost, large-context windows and agentic tool chains still demand significant compute resources. Running at scale may still be expensive.
-
Hallucinations & reliability: No model is perfect. Complex reasoning chains and multi-tool workflows may accumulate error propagation, overconfidence, or unexpected outputs.
-
Domain gaps: Fine-tuning may still be required for niche or specialised domains (e.g., legal-tech, highly regulated industries) to ensure appropriate behaviour.
-
Infrastructure/ops complexity: Deploying agentic models with tool-invocations means building backend pipelines, tool integrations, monitoring and orchestration. It’s more complex than a simple chatbot.
-
Ethical & regulatory risks: With great power comes scrutiny. Models that can reason, act, and chain tools raise governance questions: Who is accountable? What controls exist?
-
Open source means responsibility: While openness is a strength, it also means you must manage exposures, governance, version control, and updates — you’re less protected than with a closedaaS model with built-in SLAs.
9. Why This Release Could Be a Turning Point
9.1 From conversational to agentic
Many earlier LLMs were built for dialogue — answer my question, chat with me. Kimi K2 Thinking is designed for action: plan, orchestrate, call tools, evaluate. This shift has implications: more automation, more workflows, more “smart agent” behaviour rather than just “smart chat”.
9.2 Opening up high-capability models
For years, the top end of LLMs (trillions of parameters, large infrastructure) was mostly closed or expensive. Kimi K2’s open-weight licensing introduces higher-capability models into the accessible developer/enterprise ecosystem. This may accelerate innovation, disrupt vendor lock-in, and democratize agentic AI.
9.3 Long-context and tool-use convergence
Large context windows + tool invocation = new kinds of applications. Large-document reasoning, code-base reasoning, enterprise workflows over long time horizons — these are more feasible now. Kimi K2 is one of the first models to bring all these together at scale.
9.4 Competition and global AI dynamics
From an industry standpoint, Moonshot’s release signals a more competitive global AI environment. By offering high performance, open licensing, and broad accessibility, the model raises the bar — meaning proprietary players will need to accelerate or adapt.
10. FAQ – Frequently Asked Questions
Q1: What exactly is “Kimi K2 Thinking”?
A: It is a variant in the Kimi K2 model series by Moonshot AI, tailored for deep reasoning, tool-invocation and long-horizon tasks. It combines a 1 trillion parameter MoE architecture (32 billion active) with a 256 k token context window and optimizations for inference. Hugging Face+1
Q2: How does it compare with GPT-4 or Claude?
A: According to published benchmarks, Kimi K2 (and specifically the “Thinking” variant) surpasses many leading open-weight models and even some proprietary models on certain tasks like reasoning, tool chains, and coding. Venturebeat+1 However, direct apples-to-apples comparisons are still evolving and may depend on context, domain, fine-tuning.
Q3: Is the model freely available?
A: Yes — at least in variant form. Moonshot has released model checkpoints under a Modified MIT licence, making them accessible for research and development. Medium
Q4: What kind of tasks is it best suited for?
A: The model excels in multi-step reasoning tasks, code generation/bug fixing, tool invocation workflows, long-document analysis, agentic workflows (e.g., “read this, call API, summarise, plan next step”).
Q5: What infrastructure do I need to run it?
A: While the active parameter count (32B) is lower than the full 1T total, the model is still heavy. Quantisation helps, but expect to require high-end GPUs/TPUs or cloud infrastructure supporting large memory and inference speed, especially if you use the full 256 k context window or multiple concurrent users.
Q6: What are the risks / limitations?
A: As noted above: hallucinations, cost/infrastructure, domain adaptation, operational complexity, and governance/ethics concerns remain. The “thinking agent” paradigm means more autonomy — which means more need for guardrails.
Q7: How can I integrate it with existing workflows?
A: Use the model via API (Moonshot provides endpoints), integrate it into tools or pipelines where you need reasoning + action. Fine-tune on domain data if needed. Build tool-invocation layers (APIs, functions) that the agent can call. Monitor chain behaviour.
Q8: What’s next for the model or for Moonshot AI?
A: Moonshot signals further improvements: possibly larger context windows, multimodal extensions (vision/audio), more efficient inference (Llama-style smaller models but reasoning-capable), and broader commercialisation. Multi-agent integration, enterprise-grade deployments, and vertical specialisations may follow.
11. Looking Ahead: What to Watch
-
Competition from other open-source models: As Kimi K2 Thinking raises the bar, rival projects will accelerate. Architecture innovations, training regimes, cost optimisations will follow.
-
Tool ecosystem growth: To harness agentic capability we’ll see growth in standardised tool-invocation frameworks, APIs, “agent” orchestration platforms.
-
Enterprise adoption: Will we see large corporations deploying models like Kimi K2 Thinking internally (on-prem, private cloud) for critical workflows (legal, healthcare, engineering)? I believe yes.
-
Regulation & governance: As agents become more autonomous and powerful, regulators will pay closer attention — audits, transparency, safety protocols will matter.
-
Hardware and inference innovations: To make 256 k-token, 32 B-active parameter models deployable at scale, hardware and inference stack improvements are essential (cheaper GPUs/TPUs, better memory architecture, quantisation, sparsity).
-
Fine-tuned vertical models: We may begin to see versions of Kimi K2 (or its derivatives) specialised for domains such as law, medicine, science, code engineering, each with fine-tuning or adapter layers — and that can often outperform generalist models in their niche.
12. Conclusion
In sum, Kimi K2 Thinking by Moonshot AI stands out as a landmark release in the LLM space. It combines scale, architecture innovation (MoE), tool-invocation capabilities, long-context support, open licensing, and competitive performance. For developers, researchers, and enterprises, it opens up new possibilities: building agents that think, plan, act, not just respond.
But as with any major technological shift, success depends on how well we manage infrastructure, domain alignment, tool orchestration, safety, and costs. The roadmap is promising: if this model proves robust in real-world deployment, we may look back and say this was a turning point — the moment agentic AI became broadly accessible.
For quick updates, follow our whatsapp –https://whatsapp.com/channel/0029VbAabEC11ulGy0ZwRi3j
https://bitsofall.com/how-to-create-ai-ready-apis-complete-developers-guide-2025/
https://bitsofall.com/https-yourblogdomain-com-deepagent-unpacking-the-next-gen-ai-agent-revolution/
How to Design a Persistent Memory and Personalized Agentic AI System with Decay and Self-Evaluation
OpenAI Introduces IndQA: A Cultural-Reasoning Benchmark for India’s Languages

